次世代プロセッサはダイナミックな電圧制御と並列処理手法が決め手:スプリング・マイクロプロセッサフォーラム・ジャパン2006から(3/3 ページ)
消費電力を上げずに性能を上げるマイクロプロセッサが回路とアーキテクチャの2つの工夫で実現できる。回路的には動作状態に応じて電源電圧と基板バイアスをダイナミックに変える方法が主流になりそうだ。アーキテクチャ上はこれまでのメインフレームの実現に使われてきた各種の並列処理技術をプロセッサに応用するようになってきた。スプリング・マイクロプロセッサフォーラム・ジャパン2006では、このような方向がはっきり見えてきた。
マルチスレッドで効率60%に
米MIPS Technologies社は、最大で5つのスレッドを使うことでパイプライン構造のCPU実行効率を高める32ビットCPUコアファミリ「MIPS 32 34K」の詳細を明らかにした。
MIPS 32 34Kは、同社の前世代の製品「24KE」をベースにマルチスレッド機能を追加した。24KEでは、アプリケーションを実行する際に、負荷が多ければ多いほどキャッシュミスが増加する傾向があった。これに対し34Kでは、マルチスレッド機能を実装し、CPUの実行効率の向上を図った(図4)。
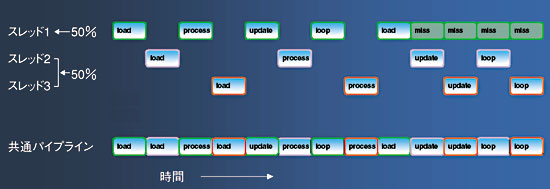
同社によると、「EEMBCのベンチマークテストであるOSPFとPKFLOWを同時に処理した場合に、34Kの命令実行効率は、24KEに比べて約60%向上した」という。また、1MHz当たりの消費電力は1.0V動作時で0.59mWと小さく、シングルスレッドの24KEとほぼ同等である。ミップス・テクノロジーズでソリューション・アーキテクトを務める豊田仁氏は、「これまで24KEでCPUが待ち状態時であった場合でも、電力を消費していた。消費電力は同等を維持できる」と述べた。
34Kのコア面積は、90nmプロセスで製造した場合に、TC(thread context)を4個、VPE(virtual processing element)を2個使ったもので5.1mm2と小さい。それぞれの占有面積は、TC 1個につき0.1mm2〜0.2mm2、VPE 1個につき0.2mm2〜0.3mm2である。
マルチコアで4GHz相当DSP
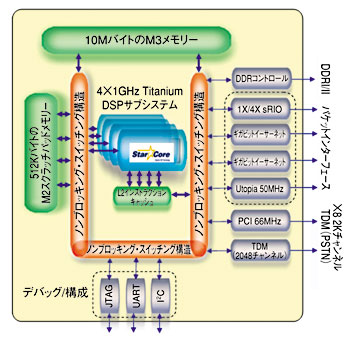
Freescale Semiconductor社は、2006年5月に発表した4GHz相当の演算性能を実現するDSP製品MSC8144の詳細を明らかにした。MSC8144は、最大1GHzで動作するDSPコア「StarCore」(米StarCore社製)を4個実装したマルチコアDSP(図5)。16GMACs(160億回/秒)の積和演算ができる。
DSPコア周辺回路における性能面での最大の工夫は、同社従来製品では5段構成であったパイプラインを12段としたこと。この12段という値は、目標性能を達成するためにシミュレーションによって決めた。
また、MSC8144の大きな特徴として、プログラム/データ用に10Mバイトの大容量メモリーを備えている点が挙げられる。これにより、多くのアプリケーションでは外部メモリーへのアクセスが不要となり、部品点数削減や低消費電力化が実現される。DSP部分は90nmのSOIプロセスを使用しているが、メモリーは90nmのバルクシリコンを採用しており、2つのチップを29mm×29mmのFCBGAパッケージに収容する。
結果として、1GHz動作での消費電力は、5.4W程度に抑えられる見込みだ(フリースケール・セミコンダクタ・ジャパンのネットワーキング&コンピューティングシステムグループ DSPオペレーションのハラダ・ウゴ・ケンジ・ペレイラ氏)。
クワッドコアで性能バランス
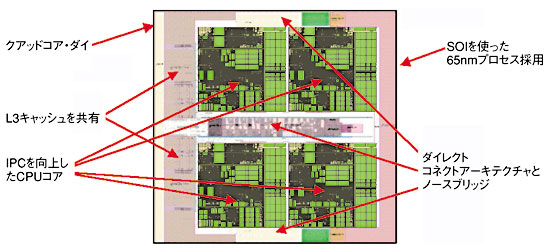
AMD社のマイクロプロセッサ・ソリューション部門でシニアフェローを務めるScott White氏は、65nmプロセスを採用した次世代の「クアッドコア・プロセッサ」を発表した(図6)。このプロセッサは、1つのダイに4つのコアを搭載し、それぞれのコアがL3キャッシュを共有する。またIPC(instruction per clock:1クロック当たりの実行命令数)を増やし、浮動小数点演算性能は2倍に上げた。
AMD社はこれまで、低消費電力と高性能を両立させる技術として、マルチコア化を推進し、開発を進めてきたが、マルチコアのコア数は何個まで並列にできるかとの質問に対し、「今のところは8個程度まで」と同氏は答えた。
超並列演算も消費電力を下げる
並列処理が消費電力を下げる方向に働くことは、並列処理を強く進めた超並列処理にも消費電力削減の効果があることが分かった。
米Connex Technology社は、小さな演算器を32×32個すなわち1024個並べてベクトルプロセッサ技術を応用し安価なHDTV向けLSIを開発中だ。演算器1個に、8本の16ビット・レジスタを積み重ね、その上に256ビットのRAMを搭載している。最も下のレジスタR0の下に16ビットのALUや選択フラグ、インデックスなどを置き、演算できるようになっている。
このセル同士の接続は、レジスタR0を32個直接接続しており、レジスタからレジスタへとデータのやりとりを行う。例えば、選択されたすべてのセルが同じ命令ストリームを実行する。
並列演算ができるため、内部I/Oの帯域幅は400Gバイト/秒と速い。しかも、積和演算や浮動小数点演算を行う必要がない。現在、TSMC社において130nmプロセスでチップを製造しているところだという。チップ面積当たりの性能は、2GOPS/mm2であり、GOPS/W性能も従来のシーケンシャルな演算処理に比べ25〜50倍高いという。DCT演算に要する性能は、0.35クロックサイクル/ピクセルと、少ないクロックサイクルで演算できるため、消費電力が少なく済んでいる。
クロックレスで並列処理
やはり映像処理を狙い、6×4セルのアレイを並べたビデオプロセッサを米IntellaSys社が開発した。SEA(scalable embedded array)と呼ぶ1個のセルは18ビットのプロセッサから成る。18ビット幅のRAMやI/O、ALU、命令セット、データレジスタ、デコード回路、ROMなどを内蔵している。命令セットは30しか持たない。
クロックを使わない非同期式で動作するため消費電力は下がる。各プロセッサセルは、1nsごとにForth命令を1つ実行する。18ビットレジスタの中に4命令を持つ。コア同士のやりとりはやはりレジスタを通して行う。レジスタは18本のデータ線と2本のハンドシェーク線を持ち、ハンドシェーク線でデータのやりとりを行う。
試作中の6×4アレイ構成のチップは、2.7mm2の面積、80パッド、144ピンのBGAパッケージに収容されている。性能は48000MIPS/Wで、消費電力は最大500mWと小さい。
NTTドコモ 移動機開発部長 千葉 耕司氏に聞く
「低消費電力化は電源制御技術がカギ」
携帯端末の開発動向は、形状的に見ると、小型、軽量で薄型化が進んでいる。加えて、充電1回当たりの使用時間を長くする、接続品質が保たれる、などが挙げられる。こうした基本要求は技術的に矛盾することが多い。例えば、携帯電話機は小型化すると体積が少なくなり、アンテナ特性が十分にとれない。また、マルチメディア化が進み、表示の画面サイズや画素数が大きくなると、その分データ処理量が増え、消費電力も増加する傾向にある。
これに対してNTTドコモで移動機開発部長を務める千葉耕司氏は、「携帯電話機の低消費電力化のカギを握るのは電源制御である。電源制御ICがうまく働かないと、どんなに優れたプロセッサでも(カタログに記載された)携帯電話機のバッテリ使用時間は守れない」と電源回りの設計が重要になっている現状を語る。
NTTドコモは2004年からルネサス テクノロジおよびTI社と、別々に3G携帯電話機向けチップを共同開発しているが、技術課題の1つが消費電力の増加だ。共同開発しているルネサス テクノロジが2006年のISSCCや今回のフォーラムで発表した低消費電力化技術にその対策が盛り込まれている。
関連キーワード
マルチコア | Cortex | フリースケール・セミコンダクタ | 富士通研究所 | ルネサステクノロジ | NECエレクトロニクス | Texas Instruments | NTTドコモ | high-kメタルゲート | ミップス・テクノロジーズ | システムLSI | ARM
Copyright © ITmedia, Inc. All Rights Reserved.