- プロセスエンジニアの現場から
- マイクロプロセッサ懐古録
- 中堅技術者に贈る電子部品“徹底”活用講座
- たった2つの式で始めるDC/DCコンバーターの設計
- DC-DCコンバーター活用講座
- Wired, Weird
- マイコン講座
- Q&Aで学ぶマイコン講座
- 高速シリアル伝送技術講座
- 記録計/データロガーの基礎知識
- アナログ設計のきほん/ADCとノイズ編
- めざせ高効率! モーター駆動入門講座
- Bluetooth mesh入門
- 「SPICEの仕組みとその活用設計」最新記事一覧
- 計測器メーカーから見た5G
- USB Type-Cの登場で評価試験はどう変わる?
- IoT時代の無線規格を知る【Thread編】
- IoT時代の無線規格を知る【Z-Wave編】
予知保全システム構築で直面しやすい“3つの課題”とその解決法:予知保全に特化したMATLABソリューションが登場
機器、システムが故障する時間、場所を“予知”し、適切なタイミングで修理、メンテナンスを行う『予知保全』が大きな注目を集めている。ただ予知保全の導入は、容易だとは言い難く、導入を阻む“3つの課題”が存在する――。本稿では、予知保全システム導入を阻む3つの課題を解決する方法を提案する。
故障まで、残り100時間――。
機器、システムが故障する時間、場所を“予知”し、適切なタイミングで修理、メンテナンスを行う『予知保全』が大きな注目を集めている。
センサー技術の進化によって、機器/システムの状態を詳細に取得できるようになり、取得したそれら状態データを、機械学習やディープラーニングなど最新のデータ処理を行うことで機器/システムの将来を予想することが可能になり、“予知保全”が行えるようになった。
下の図は、発電用風力タービンのキーパーツであるベアリング軸受の“故障予測”の様子である。
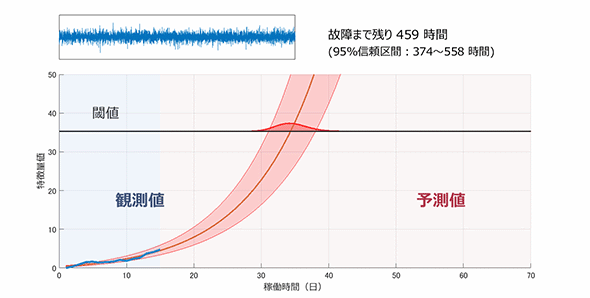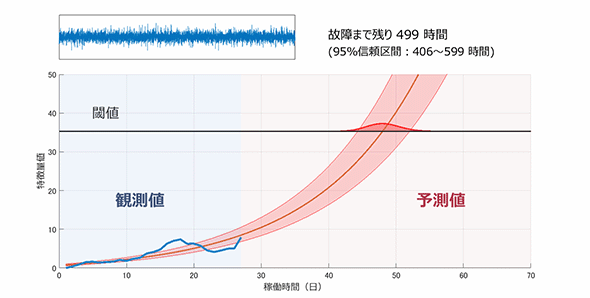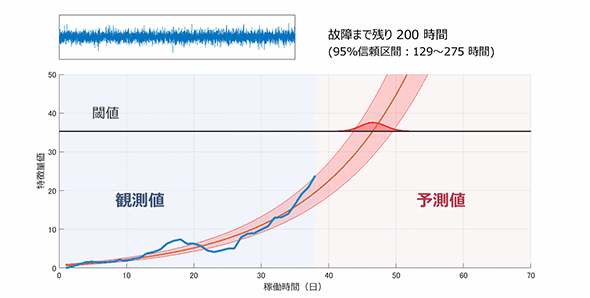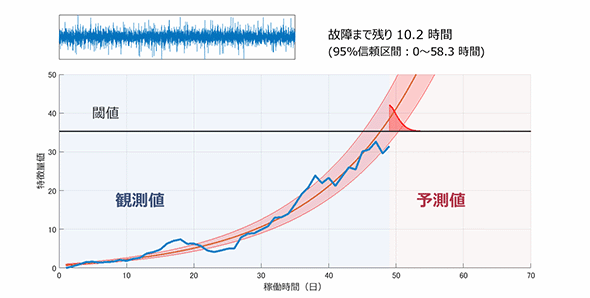 発電用風力タービンのキーパーツであるベアリング軸受の“故障予測”イメージ
発電用風力タービンのキーパーツであるベアリング軸受の“故障予測”イメージベアリング軸受の実際の振動を加速度センサーで取得。それまでの観測データを随時処理し、ベアリング軸受が「あと何時間後に故障するか」を予測し、表示している様子が分かるだろう。
こうした故障予測が可能になったことで、保守/メンテナンスの在り方は大きく変わりつつある。不測の故障に見舞われ、長時間、機器の稼働が停止し、多大な機会損失を生むようなことはなくなる。また、不測の故障を防ぐため、自動車のオイル交換のように、経験則に基づき、故障前に保守/メンテナンスを定期的に行う“予防保全”と比較しても、無駄がなく、効率の良い保守/メンテナンスを実行できるようになる。
こうした利点を多く持つ予知保全は、冒頭に紹介した風力発電システム以外にも、航空機エンジンや重機など保守/メンテナンス規模の大きい領域や、熟練技師の不足などの課題を抱えるさまざま生産現場などでも期待を集め、導入を模索する動きが活発化している。ただ、センサー技術やデータ処理技術の進化により、故障予測が可能になったとはいえ、予知保全の導入は、容易だとは言い難く、導入を阻む壁が存在している。
直面しやすい3つの課題
予知保全の導入にあたって、直面しやすい課題が大きく3つある。1つ目は、『そもそも故障予測をどうやって実現してよいのか分からない』ということだ。故障予測モデルを作成するには、高度なデータ処理技術、統計処理技術などが必要であり、そうした専門知識がなければ、何から着手すればよいかという所から困難に直面することになる。
仮に、故障予測モデルの構築方法にメドが付いたとしても、今度は高精度の故障予測モデルを作成するために必要な『データが十分に確保できない』という課題に直面することになる。特に発生頻度が少ない故障に関するデータは収集しにくく、故障予測モデルの構築を大きく阻む要素となる。
課題を乗り越え、故障予測モデルを構築しても『実際のシステムにどうやって実装/統合すればよいか分からない』という課題が最後に待ち構える――。
このように予知保全システムの導入には、『故障予測をどうやって実現してよいのか分からない』『データが十分に確保できない』『故障予測モデルをどうやって実装/統合すればよいか分からない』という3つの課題を乗り越える必要があるのだ。
しかし、予知保全で直面しやすいこの3つの課題を全て、解決できる方法が存在する。それは、MathWorksが提供する予知保全ソリューションだ。
MATLABが課題を解決
MathWorksはご存じの通り、データ解析やアルゴリズム開発、シミュレーションモデル作成などに広く使用される統合開発環境「MATLAB」を提供するベンダーである。このMATLABを用いることで、予知保全で直面しやすいこの3つの課題を解決し、予知保全システムを早期に実現、導入できるという。
予知保全アルゴリズムの開発は、大きく4つのステップがある。「データへのアクセス」「データの前処理」「予測モデルの開発」「システムへの統合」の4つであり、この4ステップ全てで、MATLABが開発をサポートする。

第1ステップの「データへのアクセス」は、センサーデータやビジネスデータが蓄積されたさまざまなデータベースにアクセスしデータを吸い出す作業だ。ここでは、さまざまなデータ形式に対応することが求められるが、MATLABでは各種データ形式に対応できるようオプション機能が用意されている。例えば、ODBCまたはJDBCに準拠したリレーショナルデータベースや各NoSQLデータベースなど一般的なデータベースへのアクセスに対応している。さらに、多くの製造現場で普及しつつある産業通信用データ交換標準である「OPC Unified Architecture」(OPC UA)準拠のOPCサーバからのデータを取得するなど、業界特化型データベースにも対応し、あらゆるセンサーデータやビジネスデータにアクセスすることが可能だ。
第2ステップの「データの前処理」は、予測モデルを作るためにデータを扱いやすく加工するステップ。具体的には、外れ値や欠損データの除去や補間を行ったり、データ同士の時刻同期処理などを行ったりした上で、データの次元削減や特徴量抽出を行う。テキストデータでは、品詞分解して解析用途に必要な形容詞だけを抜き出すなど、数値以外のデータへの処理も容易になっている。
そして、第3ステップは、前処理を行ったデータを基に、いよいよ「予測モデルを開発する」ステップになる。近年では、予測モデルを作成する手法として機械学習の適用が注目を集めている。機械学習と一言で言っても線形回帰などシンプルなものから、ディープラーニングなど高度で複雑な手法まで多様なアルゴリズム(手法)が存在し、ニューラルネットワーク、k最近傍法、バギング決定木、サポートベクターマシン(SVM)などのさまざまな手法から最適なものを検討する必要がある。MATLABでは、予測モデルを作成する際に、これらの手法を容易に適用、それぞれの手法で得られた予測モデルの精度を視覚的に比較検証できるので、最適なアルゴリズムを瞬時に決定することができる。さらに、ベイズ最適化を適用することで、予測モデルのパラメーターをファインチューニングし、精度をより高めることもできる。
第4ステップの「システムへの統合」では、エンタープライズシステムや組み込みデバイスへアルゴリズムを実働環境システム上へ実装する。MATLABで開発したアルゴリズムは、人の手によるコードの書き直しをすることなく、組み込みアプリケーションとして実装できるだけでなく、WEBサーバやWEBサービスと連携するエンタープライズアプリケーションの一部として実行することも可能である。
予知保全システム全体の最適化をする上で、アルゴリズム開発フローの第1ステップから実装までを実施できる統一された開発環境は大きなメリットになる。
予知保全システム構築をより容易にする「Predictive Maintenance Toolbox」
予知保全アルゴリズムの開発では、データからいかに機器の異常を検知し、寿命の予測を行えるかが重要になる。そこでMathWorksは、予知保全アルゴリズム開発に特化した「Predictive Maintenance Toolbox」を提供している。
Predictive Maintenance Toolboxは、予知保全アルゴリズム開発に特化したGUIを備え、直感的な作業で操作でき、さまざまな故障予測モデルの検討、開発が行えるというToolboxだ。
故障予測モデルの開発で高度な知識/ノウハウを要求される作業の1つに、いくつもの種類がある特徴量の中から、最適なものを選ぶ「特徴量選択」がある。Predictive Maintenance Toolboxでは、この難解な特徴量選択をサポートする機能として「Diagnostic Feature Designer」アプリが備わっている。このDiagnostic Feature Designerアプリを使用すると、1度に複数種の特徴量を計算し、異常データと正常データがどのように区別されるか、データ分布を分かりやすく可視化してくれる。異常データと正常データの分布がハッキリ分かれている特徴量が最適な処理方法を直感的に把握、選択できるようになる。
 特徴量選択をサポートするアプリ「Diagnostic Feature Designer」。20種類ほどの特徴量を計算し、異常データと正常データがどのように分布するかをグラフで分かりやすく表示する (クリックで拡大)
特徴量選択をサポートするアプリ「Diagnostic Feature Designer」。20種類ほどの特徴量を計算し、異常データと正常データがどのように分布するかをグラフで分かりやすく表示する (クリックで拡大)Predictive Maintenance Toolboxで作成できる「寿命(RUL:Remaining Useful Life)予測モデル」は、冒頭に紹介した発電用風力タービンのベアリングのように、正常と異常の間に特徴量のしきい値を設け、「故障まで残り○○時間」というような予測を行う「劣化モデル」の他にも、故障までのセンサーの履歴情報が多数ある場合に有効な「類似性モデル」、故障までにかかった時間情報がある場合に有効な「生存モデル」などに対応。収集したデータに合わせて最適な寿命予測モデルを構築できるようになっている。
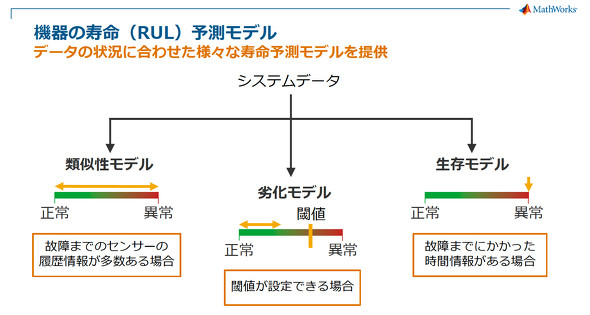 「Predictive Maintenance Toolbox」は、データ状況に合わせてさまざまな寿命予測モデルを提供する
「Predictive Maintenance Toolbox」は、データ状況に合わせてさまざまな寿命予測モデルを提供するこのように、Predictive Maintenance Toolboxの登場で、より簡単に寿命予測モデルを構築できるようになり、『故障予測をどうやって実現してよいのか分からない』という課題は解決されるが、モデルを作成するためのデータを十分に確保できないという課題が待ち受ける。
MathWorks アプリケーションエンジニアリング部 部長の宅島章夫氏は「精度の高いモデルを構築するには、大量のデータが必要になる。しかも、故障時の異常データがあった方が、精度を高めやすい。しかし、異常データが発生する頻度は低く、多くの場合で異常データ、故障データが不足し、モデル構築に立ちはだかる」と指摘する。
データ不足はシミュレーションで解消
こうしたデータ不足に対しても、MathWorksは、解決策を用意している。その解決策とは、シミュレーションで故障データなど取得しにくいデータを作ってしまう方法だ。
MATLABおよびSimulinkは、自動車の開発現場などでモデルベース開発環境として普及しており、シミュレーションは得意とするところ。仮想環境(PC上)に実機(実環境)を再現し、故障を起こして、故障データを取得すれば、データの不足が補えるというわけだ。

MATLABおよびSimulinkには、物理法則を用いて対象物の動作を表現するモデルが豊富に用意され、システムの物理的な動きを仮想化した「モデルドリブンアプローチ」のシミュレーションによるデータ生成が可能だ。また、物理法則によらず、入出力データの数学的な関係を示した統計モデルでシミュレーションする「データドリブンアプローチ」にも対応している。
 「モデルドリブンアプローチ」と「データドリブンアプローチ」
「モデルドリブンアプローチ」と「データドリブンアプローチ」 MathWorksアプリケーションエンジニアリング部部長 宅島章夫氏
MathWorksアプリケーションエンジニアリング部部長 宅島章夫氏宅島氏は「データドリブンアプローチは、データに対して高精度に適合したモデル構築が可能で、任意の数学モデルを選ぶことができるといった特長がある。しかし数学モデルのパラメーターは物理的な意味を持たないために、モデルは“ブラックボックス”になってしまうなどの難点がある。一方のモデルドリブンアプローチでは、物理的挙動の本質を捉えたモデルであり“ホワイトボックス”になっており、実際のシステムに近しいシミュレーションが行える。ただし、モデルの構築には、物理領域での専門知識が必要で労力がかかるという難点がある」と説明する。
その上で宅島氏は、「MATLABおよびSimulinkでは両アプローチを融合し、ある部分はモデルドリブンで、ある部分はデータドリブンでという風に“グレーボックス”なモデルを作成し、シミュレーションデータを生成できる。“グレーボックス”モデルをもちいることで、より容易に、素早く、精度の高いシミュレーションデータを得ることができるので、仮想的な故障データとして利用できデータ不足の課題解消が期待できる」と付け加える。
MATLABなら、組み込み機器からクラウドまで展開可能
残る課題は『故障予測モデルのシステムへの実装、統合』だが、MATLABの予知保全ソリューションはこれも解決する。
「システムへの実装においては、データ転送量、計算量、運用方法などによりデバイス上、エッジ上、クラウド上などさまざまな実装先がある。基本的には、ミリ秒単位のリアルタイム処理が必要な場合、故障モデルは、システムや機器に搭載するデバイスに実装する必要がある。処理間隔が秒単位や分単位であれば、PLC(プログラマブルロジックコントローラー)などのエッジ端末への搭載が最適であり、時間単位、日単位であればオンプレミスサーバ、月単位であればクラウドサーバというように、規模の大きなコンピューティングを用いるべきだろう。故障予測モデルによっては、複数の場所に実装する必要もあるだろう」とする。

「故障予測モデルを実装、統合するプラットフォームに応じて変換することは、通常であれば難しいが、MATLABは組み込み機器からサーバまで、さまざまなプラットフォームに展開可能なツールが存在している。そのため、故障予測モデルのシステムへの展開で困ることはない」と宅島氏は言い切る。
採用事例が多数生まれているMATLABによる予知保全ソリューション
予知保全システムの構築で、直面しやすい3つの課題全ての解決を支援するMATLABの予知保全ソリューションは、既に製造現場を中心に国内外のさまざまところで採用され、効果を挙げている。例えば、ドイツの包装/製紙メーカーであるMondi Gronau社では、プラスチックフィルム工場のある機械の故障予測システムをMATLABで構築し年間5万ユーロ(約600万円)以上のコスト削減効果が得られたという。国内では武蔵精密工業がMATLABを使用し、ディープラーニングを用いた自動車部品の外観検査システムを構築し、現在、目視を行っている月当たり130万個の外観検査を自動化する見通しだ。


宅島氏は「いずれの導入事例も、導入企業が自走できるよう技術コンサルティングサービスやトレーニングなどを提供し、予知保全システム、異常検知システムの構築を支援している。それぞれの現場に応じて柔軟に適切なソリューションを提供できる点もMathWorksの強み」と話す。
MATLABによる予知保全ソリューションの導入事例は他にも多数あり、MathWorksの特設サイトで紹介されているので、参照してほしい。同特設サイトには、予知保全ソリューションに関する詳しい技術解説コンテンツも掲載されているので、MATLABによる予知保全ソリューションに興味を持った方は、ぜひ、特設サイトをのぞいてみてほしい。
Copyright © ITmedia, Inc. All Rights Reserved.
提供:MathWorks Japan
アイティメディア営業企画/制作:EDN Japan 編集部/掲載内容有効期限:2020年1月27日
Presented by
予知保全ビデオシリーズ





![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。