- プロセスエンジニアの現場から
- マイクロプロセッサ懐古録
- 中堅技術者に贈る電子部品“徹底”活用講座
- たった2つの式で始めるDC/DCコンバーターの設計
- DC-DCコンバーター活用講座
- Wired, Weird
- マイコン講座
- Q&Aで学ぶマイコン講座
- 高速シリアル伝送技術講座
- 記録計/データロガーの基礎知識
- アナログ設計のきほん/ADCとノイズ編
- めざせ高効率! モーター駆動入門講座
- Bluetooth mesh入門
- 「SPICEの仕組みとその活用設計」最新記事一覧
- 計測器メーカーから見た5G
- USB Type-Cの登場で評価試験はどう変わる?
- IoT時代の無線規格を知る【Thread編】
- IoT時代の無線規格を知る【Z-Wave編】
PCIeスイッチファブリックによるマルチホストシステムの最適なリソース展開:GPUとNVMe SSDのプールを複数のホストで共有可能に
深層学習や機械学習など膨大な処理をリアルタイムに行うためにさまざまな課題が生じています。その1つがPCIe規格そのものがもつ制限です。そこで、こうしたPCIe固有の制限がある中でも、CPUの能力をフルに活用するための優れた方法として「PCIeスイッチファブリック」を紹介する。
データセンターなどの高性能コンピューティング環境では、深層学習および、機械学習アプリケーションで生成される大量のデータを高速に処理するために、GPUの使用が増えています。しかし、アプリケーション性能の向上を狙った他のデータセンター向け革新技術の多くと同様に、GPUの使用によって新たなシステムボトルネックが顕在化しています。そのようなアプリケーションのシステム性能を向上させるために新たに導入されたアーキテクチャは、PCIeファブリックを介して複数のホストでシステムリソースを共有します。
PCIe規格(特にそのツリー形式の階層構造)により、リソースの共有方法と達成可能な共有レベルが制限されます。しかし、低レイテンシで高速なファブリックアプローチを採用することで、標準システムドライバを使ってGPUとNVMe SSDのプールを複数のホストで共有することが可能となります。
PCIeファブリックアプローチは、動的パーティショニングとマルチホスト/シングルルートI/O仮想化(SR-IOV)を採用することで、複数ホストによるリソースの共有を可能にします。PCIeファブリックは、ファブリックを横切って直接的なピアツーピア転送を行います。これにより、理想的な経路でピアツーピア転送が可能となり、ルートポートの混雑が緩和され、CPUリソースの負荷をより効率的に配分できます。
通常、GPU転送はCPUのシステムメモリにアクセスする必要があるため、エンドポイント間で共有メモリの競合が生じます。GPUがCPUメモリよりむしろ共有メモリとしてGPUに割り当てられたリソースを使う場合、GPUはデータをローカルに取り込むことができます。これにより、最初のデータがCPUを経由する必要はなくなります。このため、データ転送とアクセス時のホップおよびリンクとその結果生じるレイテンシが除去され、GPUはより効率的にデータを処理できます。
PCIeに固有の制約
PCIeの主な階層はツリー構造を持ち、ドメイン当たり1つのルートコンプレックスが存在します。このルートからスイッチとブリッジを経由してエンドポイントへと枝分かれします。リンクの階層構造と方向は固定的であるため、マルチホスト/マルチスイッチシステムに対する設計要件を満たすには犠牲を強いられます。

以下では、図1に示すシステムについて検討します。PCIeの階層構造に準拠するには、ホスト1はスイッチ1内に専用のダウンストリームポート(DSP)を持ち、そのダウンストリームポートはスイッチ2内の専用のアップストリームポート(USP)に接続されている必要があります。さらに、スイッチ2内の専用ダウンストリームポートはスイッチ3内の専用アップストリームポートに接続されている必要があります。その後のスイッチにも、同様の接続が必要です。図2に示す通り、ホスト2およびホスト3もスイッチ1と同様の方法で接続する必要があります。

最もベーシックなPCIeツリー構造を持つシステムであっても、各ホストのPCIeトポロジ内でスイッチの接続用に3つのリンクが必要です。ホストとホストの間でこれらのリンクを共有する方法は存在しないため、システムはすぐに非常に非効率的になる可能性があります。
加えて、標準PCIeに準拠した階層構造は1つのルートポートしか持ちません。マルチルートは「Multi-Root I/O Virtualization and Sharing」仕様でサポートされますが、回路が複雑となり、現在主流のCPUではサポートされません。結果として、使用中ではないPCIeデバイス(すなわちエンドポイント)は、そのホスト内で孤立し、使えないリソースとなります。多数のGPU、ストレージデバイス、それらのコントローラ、スイッチを含む大きなシステムでは、これがいかに非効率的であるか容易に想像が付きます。
例えば、ホスト1が計算リソースを全て使い果たした時にホスト2とホスト3に利用可能なリソースが残されていた場合、ホスト1からそれらのリソースが利用できると好都合であることは明らかです。しかし、それらのリソースはホスト1の階層構造の外にあるため、それは不可能です。したがって、それらは切り離されたリソースとなります。NTB(Non-Transparent Bridging)はこの問題を解決可能な方法ですが、共有PCIeデバイスのタイプごとに非標準のドライバとソフトウェアが必要であるため、システムは複雑になります。これよりも大きく優れたアプローチとして、PCIeファブリックを使う方法があります。この方法では、標準PCIeトポロジのままでマルチホストに対応でき、各ホストから全てのエンドポイントへアクセスできます。
PCIeファブリックアプローチの実装
PCIeファブリックスイッチ(この例では、Microchip社のSwitchtec PAXファミリ)を使って透過的に相互動作が可能な2つのドメイン(ホストドメインとファブリックドメイン)を持つシステムを実装します。ファブリックドメインは全てのエンドポイントとファブリックリンクおよび、ホストごとに専用のホストドメインを含みます(図3)。これらのホストは、組み込みCPU上で動作するPAXスイッチファームウェアによりホストごとに分離した仮想ドメイン内で維持されます。したがって、1つのスイッチはエンドポイントが直接接続された標準シングルレイヤPCIeデバイスであるかのように見えます。また、それらのエンドポイントは、ファブリック内で実際にどこに接続されているかに関係なく、直接そのスイッチに接続されているかのように見えます。

ホストドメインからのトランザクションは、ファブリックドメイン内でIDとアドレスによる非階層的なトラフィックに変換されます。ファブリックドメインからのトラフィックは、これとは逆に変換されます。これにより、スイッチとエンドポイントを接続するファブリックリンクは、システム内の全てのホストにより共有できます。スイッチファームウェアは、ホストからの全てのコンフィグレーションプレーントラフィック(PCIeエニュメレーションプロセスを含む)を傍受し、PCIe仕様に準拠したシンプルなスイッチを仮想化します(スイッチのダウンストリームポートの数は設定可能)。
全てのコントロールプレーントラフィックは処理のためにスイッチファームウェアへ渡され、データプレーントラフィックはエンドポイントへ直接渡されます。各ホストドメイン内の未使用GPUは、他のホストの要求に応じて動的に割り当てることが可能であるため、もう取り残されることはありません。機械学習アプリケーションに対応するため、ファブリック内でピアツーピアトラフィックがサポートされます。PCIe仕様に準拠した方法で各ホストに対して能力が提示されるため、標準ドライバが使えます。
PCIeファブリックアプローチの動作
このアプローチの動作を確認するため、図4のシステムを想定します。このシステムは2つのホスト(ホスト1はWindows対応、ホスト2はLinux対応)、4つのPAX PCIeファブリックスイッチ、4つのNvidia M40 GPGPU、1つのSamsung NVMe SSD(SR-IOV対応)で構成されます。この事例では、ホストは実際の機械学習ワークロードを代表するトラフィック(Nvidia社のCUDAピアツーピアトラフィックベンチマークユーティリティとcifar10画像分類TensorFlowモデルを含む)を実行します。組み込みスイッチファームウェアはローレベルでのスイッチの設定と管理を処理し、Microchip社のChipLinkデバッグ/診断ユーティリティがシステムを管理します。

4つのGPUは内部でホスト1(Windowsホスト)に割り当てられ、PAXファブリックマネージャはファブリック内で見つかった全てのデバイスをホスト1に結合されたGPUと一緒に表示します。しかしホストからはファブリックの複雑な構造は見えず、全てのGPUは仮想スイッチに直接接続されているかのように見えます。ファブリックマネージャは全てのデバイスを結合し、Windowsデバイスマネージャは全てのGPUを表示します。ホストからは、スイッチが設定可能な数のダウンストリームポートを備えたシンプルな物理PCIeスイッチであるかのように見えます。
CUDAが4つのGPUを見つけると、ピアツーピア帯域幅テストにより単方向転送が12.8GB/秒に達し、双方向転送が24.9GB/秒に達することが示されます。これらの転送は、ホストを経由することなくPCIeファブリック内で直接行われます。Cifar10画像分類アルゴリズムを学習するTensorFlowモデルは、処理負荷を4つのGPUの全てに分散させて実行します。その後、2つのGPUをホストから切り離してファブリックプールへ戻すことができます。これら2つのGPUには他の処理を実行させることができます。Linuxホストからも、カスタムドライバを必要としないシンプルなSPIeスイッチであるかのように見え、CUDAはGPUを検出しピアツーピア転送をLinuxホスト上で実行します。性能はWindowsホストもLinuxホストもほぼ同等です(表1参照)。
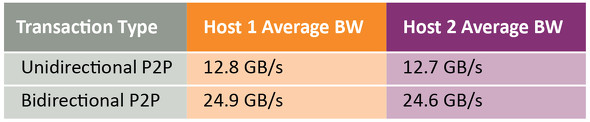 表1:GPUピアツーピア転送の帯域幅
表1:GPUピアツーピア転送の帯域幅次のステップでは、SR-IOV仮想機能をWindowsホストにアタッチします。これにより、ホストにはPAXが標準物理NVMデバイスとして提示され、標準NVMeドライバを使うことができます。この後に、仮想機能はLinuxホストにアタッチされ、新しいNVMeデバイスがブロックデバイスリストに表示されます。以上により、両方のホストがそれぞれの仮想機能を使えるようになります。
重要なことは、ホストから見える仮想PCIeスイッチと全ての動的割り当て動作はPCIe仕様に完全に準拠しているため、ホストは標準ドライバを使うことでできるということです。組み込みスイッチファームウェアが提供するシンプルなマネジメントインターフェイスにより、低コストの外部プロセッサによってPCIeファブリックを設定および管理できます。デバイスのピアツーピアトランザクションは既定値により有効となるため、外部のファブリックマネージャから追加で設定または管理する必要はありません。
まとめ
PCIe規格そのものによる制限はありますが、PCIeスイッチファブリックはCPUの能力をフルに活用するための優れた方法です。これらの制限には、動的パーティショニングとマルチホスト/シングルルートI/O仮想化によるリソースの共有により対応できます。これにより、GPUおよび、NVMeリソースをマルチホストシステム内の任意のホストに動的に割り当てることで、機械学習が要求する処理負荷の変化にリアルタイムに適応することができます。
【著:Vincent Haché/Technical Staff, FW Engineering, Microchip Technology】
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
提供:マイクロチップ・テクノロジー・ジャパン株式会社
アイティメディア営業企画/制作:EDN Japan 編集部/掲載内容有効期限:2020年12月4日
関連リンク

![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。