- プロセスエンジニアの現場から
- マイクロプロセッサ懐古録
- 中堅技術者に贈る電子部品“徹底”活用講座
- たった2つの式で始めるDC/DCコンバーターの設計
- DC-DCコンバーター活用講座
- Wired, Weird
- マイコン講座
- Q&Aで学ぶマイコン講座
- 高速シリアル伝送技術講座
- 記録計/データロガーの基礎知識
- アナログ設計のきほん/ADCとノイズ編
- めざせ高効率! モーター駆動入門講座
- Bluetooth mesh入門
- 「SPICEの仕組みとその活用設計」最新記事一覧
- 計測器メーカーから見た5G
- USB Type-Cの登場で評価試験はどう変わる?
- IoT時代の無線規格を知る【Thread編】
- IoT時代の無線規格を知る【Z-Wave編】
理想的なインターコネクトの特性とは:オープンコンピューティング向けインターコネクト[前編](3/4 ページ)
トランザクションタイプ
キャッシュコヒーレンシ
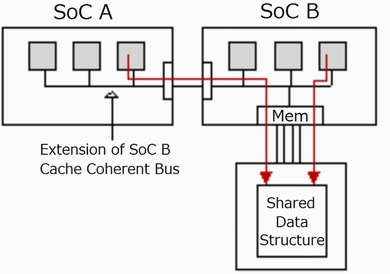 図2:キャッシュコヒーレント異種マルチプロセシング
図2:キャッシュコヒーレント異種マルチプロセシング理想的なインターコネクトは、デバイス間で共有されるメモリ領域向けにキャッシュコヒーレンシプロトコルに対応し、共有されたメモリデータ構造へのアクセスのために、プログラミングモデルを簡素化し(図2を参照)、複数のSystem on Chip(SoC)全体で効率的なプロセス間通信を可能にします。キャッシュコヒーレントバスの拡張によって、インターコネクトの電力に対する演算に要する電力の比を変えることができます。例えば、ファイルシステムアプリケーションのパフォーマンスは、インターコネクトによってほとんど定義上制限されます。対照的に、素数の検索は、見つかった比較的小さな素数の量を伝送する速度ではなく、検索しているプロセッサの個数によって制限されます。このため、キャッシュコヒーレンシにより、現在実行中のアプリケーションの演算リソースとI/Oリソースを最適なバランスにすることを達成するためにシステム内のノードの構成とサイズを変更することができます。演算とI/Oリソースのバランスをとることで、演算とI/Oオペレーションに使用する全エネルギーを、有用なアプリケーション処理に費やすことができます。
バス拡張のリード/ライト
残念ながら、キャッシュコヒーレンシに必要な帯域幅の量は、システム規模が成長するにつれ、急激に拡大します。そのため、キャシュコヒーレント・エクサスケールコンピュータは簡単に、実現可能ではありません。理想的なインターコネクトは、より大規模なシステムに効率的に合わせて拡張するために、内部SoCバスの非キャッシュコヒーレント拡張に対応するでしょう。
一般的に、内部SoCバスはリードとライトのトランザクションに対応し、そしてソフトウェアエンティティ間の通信と相互排他処理のような、複雑な処理やアトミックトランザクションに対応することもあります。図3に示すように、理想的なインターコネクトはSoCバスを効率的に拡張できます。理想的なインターコネクトは、リード/ライト・トランザクションが常に、SoCバスのプログラミングモデルが守る予想可能な順番で、ターゲットメモリに到達することを保証しなければなりません。さらに、理想的なインターコネクトは、レイテンシを低減するために、全てのデータが届く前に、トランザクションで制御情報(すなわち、メモリアドレス、デスティネーション、トランザクションタイプ)を検証する仕組みを提供しなければなりません。このようにして、処理の遅れはメモリコントローラと内部バスにおいて複雑な命令やリードレスポンス、ライトの処理をするよりも前に、受け取った各I/Oトランザクションに関連するデータが正しいことを確認する処理に限定されます。
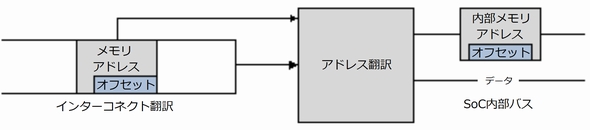 図3:内部バスへ直接マッピングするリード/ライトパケット
図3:内部バスへ直接マッピングするリード/ライトパケットメッセージング
多くのシステムは、ダイナミックなトポロジがあります。結果として、アプリケーションは安全で効果的にリードとライトのトランザクションを完了する場所を見つけなければなりません。しかしながら、ノードと通信するために利用可能な唯一のツールがリードとライトである場合、そのノードでリードやライトをする場所を知ることは、「卵が先か鶏が先か」の問題になります。このパラドックスを避けるために、メッセージング命令が導入されました。メッセージがレシーバによって正しく処理されるためには、メモリアドレスには依存しません。その代わりに、レシーバが選択したメモリ領域にメッセージコンテンツと関連するメタデータを置くかはレシーバ次第です。大容量の転送と長く続く転送、接続先特有の転送、もしくはいずれかの場合では、各転送の完了までに転送先となるメモリアドレスを調整するためにメッセージは使われます。一時的な接続や小容量な転送、コネクションレス転送の場合、メッセージ命令が最適です。
リードとライト同様に、メッセージのインオーダー配信を理想的なインターコネクトが保証すると、メッセージング通信は非常に効果的です。加えて、理想的なインターコネクトはコネクション型とコネクションレス型メッセージングに対応します。受信されたメッセージが多種多様のプロセスやアプリケーション特有のキューの1つにルーティングできたり、これらのキューのコンテンツがソフトウェアで直接アクセスできたりするようにすべきですが、これらは必須ではありません。
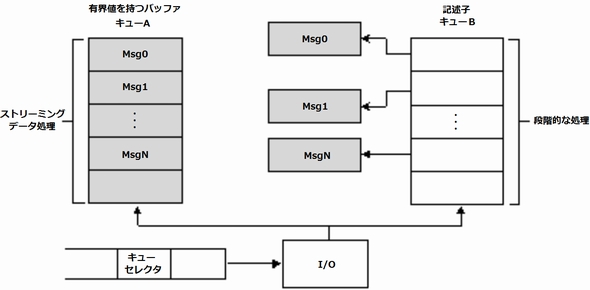 図4:プロセス特有の記述子志向のメッセージングキュー
図4:プロセス特有の記述子志向のメッセージングキューRDMA
リード/ライトとメッセージング命令の理想的なインターコネクトの組み合わせによって、Remote Direct Memory Access(RDMA)という3つ目の能力が可能となります。RDMAプロトコルはメッセージを使用して、リードとライトについてリモートでアクセス可能なメモリ領域の使用を調整します(図5を参照)。RDMAテクノロジは、図3で示すように、リードとライトがデバイスの内部バスの命令に直接マッピングするため、異なるプロセッサ上で実行されるソフトウェアエンティティ間で、最小の処理負荷で情報転送を実現する可能性があります。内部バスと理想的なインターコネクトに統合されたDMAとメッセージングエンジンは、プロセッサからデータ転送の負担をオフロードし、実際のアプリケーション作業のためにできる限り多くのCPUサイクルを保持します。
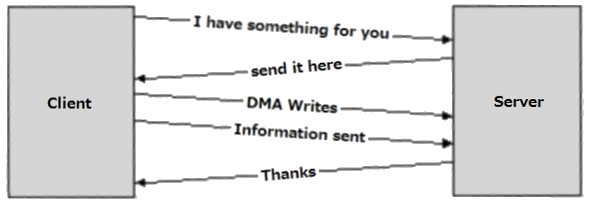 図5:RDMA領域、読取り/書込み、ポーリングの設定に使用されるメッセージ
図5:RDMA領域、読取り/書込み、ポーリングの設定に使用されるメッセージCopyright © ITmedia, Inc. All Rights Reserved.
記事ランキング




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。