- プロセスエンジニアの現場から
- マイクロプロセッサ懐古録
- 中堅技術者に贈る電子部品“徹底”活用講座
- たった2つの式で始めるDC/DCコンバーターの設計
- DC-DCコンバーター活用講座
- Wired, Weird
- マイコン講座
- Q&Aで学ぶマイコン講座
- 高速シリアル伝送技術講座
- 記録計/データロガーの基礎知識
- アナログ設計のきほん/ADCとノイズ編
- めざせ高効率! モーター駆動入門講座
- Bluetooth mesh入門
- 「SPICEの仕組みとその活用設計」最新記事一覧
- 計測器メーカーから見た5G
- USB Type-Cの登場で評価試験はどう変わる?
- IoT時代の無線規格を知る【Thread編】
- IoT時代の無線規格を知る【Z-Wave編】
ビデオアーキテクチャの正しい選択:ここが差異化のポイント(3/3 ページ)
機能を吸収する
ハードワイヤードのコンセプトをDSPコア内に取り入れて、それらを専用ブロックの構築に使うのではなく、携帯機器内のすべてのメディア処理を実行できる1つの高性能なDSPコアを実現するマルチメディアアーキテクチャがあることは興味深い。このアプローチでは、ビデオ処理に必要なアルゴリズムを慎重に選び、それらアルゴリズム内のホットスポットを特定し、ホットスポットを解決するための命令セット拡張機能を開発しなくてはならない。
「システムに関するさまざまなノウハウを取り入れてDSPコアのマイクロアーキテクチャを構築すれば、これらのアルゴリズムのパフォーマンスを2〜20倍も引き上げることができる」と、Analog Devices社のKablotsky氏はいう。それだけのパフォーマンスを達成できれば、例えばDSPコア「Blackfin」のみでCIFレベルのH.264デコードを約20mWの電力消費量で処理することが可能となる。しかし、計算負荷の大きいタスクをDSPコアに集中させると2つの問題が生じる。1つは、タスクの完了に必要となる命令フェッチの回数が増え、電力が余分に消費されることだ。もう1つは、コアのクロックレートが上昇し、電力消費量の増加につながることである。Kablotsky氏は、アルゴリズムに適した命令を生成することで、これらの問題を軽減できると主張する。多数の命令(例えばインナーループ全体)を1つの新しい命令に統合することで、必要とされるフェッチ回数を減らすことができる。また、マイクロアーキテクチャの拡張機能を開発し、例えばSIMD(single instruction multiple data)命令を使ってデータレベルの並列処理を行えるようにすれば、クロックレートを下げることができる。
DSP技術をライセンスする米CEVA社も同様のアプローチを取っている。同社の場合、ビデオ処理用のFST(fast subspace tracking)アルゴリズムの所有権を持つ企業の買収により、マイクロアーキテクチャを進化させている。CEVA社で販売部門のバイスプレジデントを務めるIssachar Ohana氏によれば、FSTソフトウエアはビデオ処理速度を劇的に向上させるという。FSTコード用の命令拡張を組み込んだ「CEVA-X」コアは、外部ハードウエアがなくてもD1の解像度で30フレーム/秒のH.264コーディングを実行できる。「これらのアルゴリズムを組み合わせて同コアに実行させることで、ハードウエアだけの場合と大差ない電力消費量に抑えることができる」とOhana氏はいう。
1つのDSPコアですべての演算を処理できればチップ開発は簡単だ。Kablotsky氏によれば、その大きな利点は、開発者にCレベルの単一プログラミングモデルを提供できることにある、という。システムOEMメーカーがカスタマイズしたい機能と、コーデック開発者または技術力のある設計会社がマイクロアーキテクチャのソースコードとして調整したい機能のすべてを提供できる。このアプローチにより、少なくともDSPの処理能力と電池の寿命がユーザーの要件を満たしている限り、システムアーキテクチャの修正と拡張を容易に行うことができる。
3つ目の例は、英ARM社のプロセッサコアに見ることができる。ARM社でテクノロジマーケティング部門のバイスプレジデントを務めるKeith Clarke氏は、単一CPUからマルチメディアプロセッサへの進化を見てきた。「ARM7」は一部のオーディオアプリケーションに適している。しかし、「ARM9」の16ビット飽和算術命令とスピードがあれば、オーディオだけでなく、約80MHzで15フレーム/秒のMPEG-4 QCIF(quarter CIF)エンコードにも対応できる。「ARM11」の動作周波数を上げ、V6命令セットアーキテクチャのSIMD命令を加えれば、VGA解像度のH.264エンコードが可能である。一歩進めて64ビットSIMDアーキテクチャの「Cortex A8」と「NEON」アクセラレータを追加すれば、30フレーム/秒のMPEG-4、VGAエンコードをARM11の約半分のサイクルタイムで実行できる(図3)。リアルタイム処理を行うためには約300MHzの動作周波数が必要となる。これらのオプションを実現するため、ARM社は現在、並列にデータを抽出して処理するSIMDハードウエア向け並列コンパイラのプロトタイプを開発している。
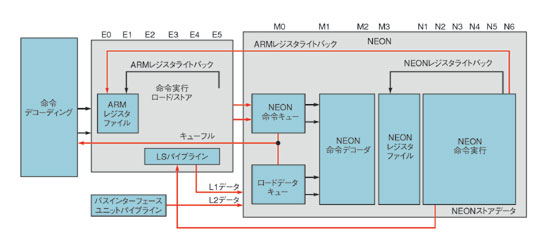 図3 ARM社のマルチメディアプロセッサ CortexA8アーキテクチャを採用したNEONSIMDプロセッサはCortexCPUパイプラインと連動することで高効率を実現している。
図3 ARM社のマルチメディアプロセッサ CortexA8アーキテクチャを採用したNEONSIMDプロセッサはCortexCPUパイプラインと連動することで高効率を実現している。マルチコアへ
高度に最適化されたDSPまたはCPUコアを使うことが必ずしも最終的な答えとは限らない。Analog Devices社、ARM社、CEVA社は、例えば、セットトップボックスが複数のHD(高品位)データストリーミングを処理するにはマルチコアが必要かもしれないことを示唆している。米Cradle Technologies社などのメーカーも、カスタマイズDSPに基づいたマルチコアに焦点を当てている。同社は、共有メモリーの周辺に、完全にプログラマブルな非対称DSPコアを配置している。適切なDSPコアに適切な拡張機能を持たせ、そのコアのローカルメモリーに必要なデータを渡すのがシステムアーキテクチャの基本である。「アプリケーションのシナリオとアルゴリズムを深く理解している設計者は、こうしたことのすべてを決定しなくてはならない」とCradle社アプリケーション部門バイスプレジデントのBruch Schulman氏はいう。
Schulman氏によれば、重要なことの1つは、アプリケーションを適度な大きさのブロックに分割することだ。ブロックの処理能力が小さすぎるのに各ブロックが処理を始めると、オンチップの共有メモリーとのトラフィックが大きくなりすぎ、システムのスループットは低下する。各ブロックが処理能力を超えると、チップはそのアプリケーションでの並列タスクを実行できなくなる。もう1つ重要なことは、機能ブロックのデータフローを理解し、プログラム制御の下でプリフェッチを実行させることだ。そうすれば、処理ブロックがデータを待つことがなくなり、チップは外部DRAMを効率的に使うことができる。
システマチックなアプローチ
システムアーキテクチャには、設計者の分析結果や労力、組織の慣行、伝統が反映されている。メーカーは最初に成功したアーキテクチャのアイデアに偏りがちだが、それでも数多くのパターンが生まれていることは、映像に重点を置いたマルチメディア対応のアーキテクチャ設計にシステマチックなアプローチが取れることを示唆している。そうしたアプローチを行うには、社内とかサードパーティとかに関係なく、コーデックとアプリケーションの開発者と緊密な関係を築く必要がある。それらの知識がなければ満足な結果は得られない。逆にそれができれば、システム設計者はシステムのタスクレベルのモデルから始め、顧客のニーズに合ったデータフローを完結できる。
このモデルから、設計者はまず、データ処理にかかわる演算上のホットスポットを見つける必要がある。つまり、多くの時間と電力を消費するコードシーケンスだ。パイプライン、SIMDエンジン、ステートマシンなどの従来のアプローチを行えば、設計者は特定のハードウエアでこれらのホットスポットを管理できる。これらのアクセラレータは必ずしもすぐに実装する必要はない。しかし、少なくとも加速されるコードシーケンスの実行時間と消費電力を低減することが可能である。
次に設計者は、システム全体に必要とされるブロック間の帯域幅が最小になるように、タスク全体を大きなブロックに分割することができる。例えば、動き検出やハフマン符号化に対応する機能を1つのブロックにすることが考えられる。この工程は非常に重要だ。今日の技術では、演算にそれほどのコストはかからないが、帯域幅は消費電力に大きく影響する。すべてのブロックを特定したら、データフローに基づいてそれらを整理し、何をパイプライン処理するのかを決める。並列処理するものと、シーケンシャルに処理するものを分ける。
その後、ブロックをそのアクセラレータとともにグループ化し、システムのスループットと消費電力の要件を満たせるよう、できるだけ少ない処理部にマッピングする。数多くの拡張命令に対応した高性能なARMコア1つを使い、適切なクロック周波数で必要な処理を実行できるなら、それでもう完成である。それぞれにアクセラレータを備えたいくつもの小さなDSPが必要ならば、そのようにすればよい。つまり、最小限の演算処理ができるブロックにマッピングすることが必要である。時間があれば最適化を行い、各処理サイトに関連付けられたすべてのアクセラレータについて、リソースの競合なくハードウエアを共有できるかどうかを見る。もし共有できるなら、2つ以上のアクセラレータを1つに統合できるかもしれない。最後に、これらの処理部がCPU、DSP、あるいは専用ハードウエアのブロックのいずれであっても、ローカルメモリーを割り当てて相互に接続し、さらにメインメモリーに接続して、必要なデータフローの帯域幅を満たせるようにすればよい。
柔軟性に優れたマルチメディアプラットフォームのアーキテクチャ
Iole Moccagatta/Vincent Nollet/J-Y Mignolet ベルギーIMEC社
エレクトロニクス機器では、デジタル化によって、高品質のマルチメディアサービスと高速データ通信との統合が可能になる。この組み合わせはインターネットへのユビキタスなアクセス、つまりサービス、コンテンツ、アプリケーションがいつでも、どこででも利用できることを意味している。家庭にいても、街中を散歩しているときでも、自動車を運転中でも、距離の離れた地方にいるときでもサービスと情報が利用できる。これらを実現するには、WLAN 802.11n、3G/ 4G、802.16e、DVB-H(digital video broadcast handheld)の通信規格と、MPEG-2、MPEG-4、AVC/H.264、MPEG SVC(scalable video coding)のコンテンツフォーマットを携帯端末がサポートし、シームレスに切り替えられなくてはならない。筆者らのIMEC社はこれを可能にするために必要な技術を開発中である。
これらのシナリオを実現するマルチモードのマルチメディア端末を開発するには、設計者はいくつかの大きな技術的課題を解決しなくてはならない。マルチメディアエンコーダ/デコーダの複雑さ、通信規格間のシームレスな切り替え、機器のコスト、消費電力、そして製品化までの期間短縮などである。
IMEC社は「M4」プログラムで、これらの技術的課題を解決するためのビルディングブロックを策定している。これらのブロックには、ソフトウエア無線のフロントエンドとデジタルベースバンド、3MF(multimedia multiformat)コーデック、QoE(quality of experience)マネジャが含まれる。
M4端末の3MFコーデックは、オーディオ/ビデオ圧縮規格と3Dグラフィックス規格をサポートしていなくてはならない。そのため、IMEC社は現存のビデオ/オーディオ圧縮規格と将来の規格をサポートできる、柔軟なヘテロジニアスプラットフォームを開発した。当社はそのプラットフォーム上で電力効率に優れた新しいMPEG SVC規格の実装を実証しようとしている。現在、MPEG標準化プロセスの最終段階にあるSVCは、ITU(International Telecommunications Union)のTH.264/MPEG AVC(advanced video coding)と組み込みコンテンツのスケーラビリティを組み合わせることで、効率の高い圧縮の実現を目指している。プラットフォームリソースの使用状況、通信帯域幅、M4端末で発生しやすい伝送エラー、質の高いユーザーエクスペリエンスの確保といった、さまざまな使用条件に対応するには、コンテンツのスケーラビリティが鍵となる。しかし、圧縮性能の高さと、組み込みコンテンツのスケーラビリティを組み合わせようとすれば、事態は一層複雑になる。従って当面の課題は、柔軟なプラットフォーム上でコスト効果と消費電力に優れたSVCをいかに実装するかということである。
IMEC社は2005年に、これらの要件を満たすプラットフォームを定義した。マルチプロセッサ構成のIMEC ADRES (architecture for dynamically reconfigurable embedded systems)プロセッサとサードパーティ製IPから成るこのプラットフォームには、スクラッチパッドのデータメモリー階層があり、各ADRESプロセッサにはこの階層にアクセスするための拡張DMAコントローラが割り当てられている。
ADRESプロセッサには、粗粒度の再構成可能なアレイと、密結合のVLIW(very long instruction word)プロセッサで構成されるコアが採用されている。共同開発されたCコンパイラによって、このコアは完全にC言語でプログラムできる。最新のDSPと同等の柔軟性があり、さらに最新のASIP(application specific instruction processors)と同等の電力効率を実現する。90nmのCMOS技術で8×8個の機能ユニットを備えた32ビットADRESコアの場合、このプロセッサの電力効率は50MOPS〜70MOPS/mWとなり、ピークパフォーマンスは400MHzで約25BOPSに達する。コアとL1キャッシュを含めたチップ面積は約7mm2だ。キャッシュは、データ用に32Kバイト、命令用に128Kバイト、コンフィギュレーションメモリー用に16Kバイトが割り当てられている。
アプリケーションマッピング設計フローは革新的なマルチプロセッサSoCのアプリケーション開発を容易にした。このフローには、並列処理を可能にする「Sprint」や、メモリー階層を最適化してメモリーアクセス回数を最小限に抑える「Atomium」といったIMEC社独自の最先端設計ツールが使われている。これらのツールは、チップ上のネットワーク機能によって相互接続する異種のプロセッシングユニット(この場合はADRESコア)を搭載したプラットフォームにアプリケーションをマッピングできる。さらに、これらのアプリケーションマッピングツールにより、ADRES DMAコントローラなどのインテリジェントなDMAコントローラを使ってメモリー階層を管理したり、データ転送を最適化したりすることが容易になる。
柔軟性に富むこのプラットフォームはさまざまなビデオコーデックをサポートできるため、数々のマルチメディアアプリケーションに対応できるスケーラビリティがあり、総所有コスト(COT)を低く抑えることができる(図A)。例えば、使用されていないプロセッシングユニットを顧客がオフにすることもできる。90nmプロセスを使って製造したこのプラットフォームの消費電力は700mW以下(動作電圧1Vで最大性能時)である。HDTV解像度のH.264/AVCデコードで32フレーム/秒、VGA解像度のSVCデコードの場合、30フレーム/秒を達成する。
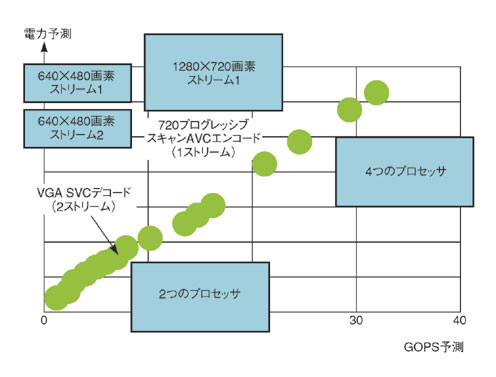 図A IMEC社のプラットフォーム ADRESプロセッサの数を増やすことでプラットフォームのパフォーマンスをスムーズに向上できる。
図A IMEC社のプラットフォーム ADRESプロセッサの数を増やすことでプラットフォームのパフォーマンスをスムーズに向上できる。Copyright © ITmedia, Inc. All Rights Reserved.
記事ランキング




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。