- プロセスエンジニアの現場から
- マイクロプロセッサ懐古録
- 中堅技術者に贈る電子部品“徹底”活用講座
- たった2つの式で始めるDC/DCコンバーターの設計
- DC-DCコンバーター活用講座
- Wired, Weird
- マイコン講座
- Q&Aで学ぶマイコン講座
- 高速シリアル伝送技術講座
- 記録計/データロガーの基礎知識
- アナログ設計のきほん/ADCとノイズ編
- めざせ高効率! モーター駆動入門講座
- Bluetooth mesh入門
- 「SPICEの仕組みとその活用設計」最新記事一覧
- 計測器メーカーから見た5G
- USB Type-Cの登場で評価試験はどう変わる?
- IoT時代の無線規格を知る【Thread編】
- IoT時代の無線規格を知る【Z-Wave編】
ハードウエアアクセラレータの実装――システム性能向上の鍵は、アーキテクチャの最適化(2/3 ページ)
ハードウエアの実装
ハードウエアアクセラレータはデータの取り込み、処理、結果の出力を自律的に行なう。システムの環境によっては、データをアクセラレータに送るためのインターフェースを必要とする場合がある。そのためこのモジュールには、CPUと接続するオンチップバスまたは外部バスへのインターフェース、およびアクセラレータとの間でデータをやりとりするDMAエンジンを組み込む必要がある。
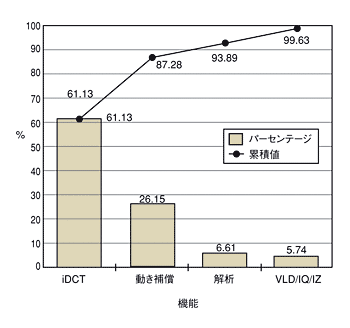 図1 MPEG-2デコード処理における各機能のヒストグラム上位レベルの機能に基づいてグループ化し、機能ごとの実行時間の割合と、それらの合計がアルゴリズム全体に占める割合を示している。,図1 MPEG-2デコード処理における各機能のヒストグラム上位レベルの機能に基づいてグループ化し、機能ごとの実行時間の割合と、それらの合計がアルゴリズム全体に占める割合を示している。
図1 MPEG-2デコード処理における各機能のヒストグラム上位レベルの機能に基づいてグループ化し、機能ごとの実行時間の割合と、それらの合計がアルゴリズム全体に占める割合を示している。,図1 MPEG-2デコード処理における各機能のヒストグラム上位レベルの機能に基づいてグループ化し、機能ごとの実行時間の割合と、それらの合計がアルゴリズム全体に占める割合を示している。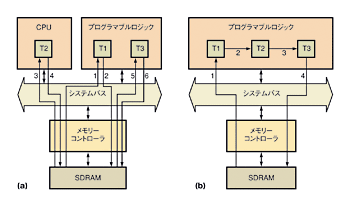 図2 T1とT3をハードウエアで実装したときのデータフローでは、T2によってシステムデータの移動が増える(a)。3つすべての変換機能をハードウエアで実装し、T1/T2間およびT2/T3間のデータ転送をハードウエアアクセラレータ内に局所化すると、システムバスを介するデータはわずか2kバイトとなる(b)。
図2 T1とT3をハードウエアで実装したときのデータフローでは、T2によってシステムデータの移動が増える(a)。3つすべての変換機能をハードウエアで実装し、T1/T2間およびT2/T3間のデータ転送をハードウエアアクセラレータ内に局所化すると、システムバスを介するデータはわずか2kバイトとなる(b)。図1のiDCT(inverse discrete cosine transform:逆離散コサイン変換)のようにマイクロプロセッサの実行時間の61%を占めるソフトウエア処理をハードウエアに置き換えても、性能が2.5倍に向上するわけではない。CPUコアとアクセラレータ間の通信オーバーヘッド、メモリーから取得したデータの格納/検索処理の効率性、およびシステムにおけるデータ位置などが処理の効率に影響を与えるからである。
アルゴリズムをソフトウエアだけで実装しているシステムでは、実行時間のほとんどがコアアルゴリズム内での算術演算に費やされる。これらのコアアルゴリズムをハードウエアに組み込めば、CPUはハードウエアアクセラレータによる処理の制御やスケジューリングを行う、いわばコントローラのような動作を行うようになる。このような組み込みは、DMA処理を構築し、レジスタビットを設定したあと、コマンドキューに命令を入れて行なうのが一般的である。
たとえば、T1、T2、T3の3つの変換関数があるとする。T1とT3はそれぞれCPUによる処理時間の30%を占め、T2は1%しか占有しない。T1、T2、T3の間で大量のデータが転送されるとき、高速化の対象からT2を除くことは、プロファイリングが示すよりも重大な影響をシステム性能に及ぼす可能性がある。
それぞれの変換関数が1kバイトのデータを読み出し、1kバイトのデータを書き戻すと仮定する。T1とT3をハードウエアで実装し、T2をソフトウエアで実装した場合、データトラフィックは6kBになる(図2(a))。T2の除外によって得られた効果を、プロファイルデータに基づいて見積もることはできない。除外によってシステムデータの移動が増えるからである。その代わり、3つの変換関数すべてをハードウエアで実装し、T1/T2間、T2/T3間のデータ転送をハードウエアアクセラレータに割り当てることができる(図2(b))。その場合、システムバスを介するデータはわずか2kバイトになる。
MPEG-2デコーダのヒストグラムを見ると、iDCT、動き補償機能に続くアクセラレータ化の候補は、パース(PARSE:解析)機能となる。しかし、アルゴリズムのデータフローを見ると、VLD/iQ/iZZ(variable-length decode/inverse quantization/inverse zigzag:可変長デコード/逆量子化/逆ジグザグスキャン)機能を高速化せずにパース機能を高速化すると、データの局所化という問題が起きる可能性が高い。したがって、VLD/iQ/iZZ機能の高速化を優先させるべきであろう。
Copyright © ITmedia, Inc. All Rights Reserved.
記事ランキング




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。