- プロセスエンジニアの現場から
- マイクロプロセッサ懐古録
- 中堅技術者に贈る電子部品“徹底”活用講座
- たった2つの式で始めるDC/DCコンバーターの設計
- DC-DCコンバーター活用講座
- Wired, Weird
- マイコン講座
- Q&Aで学ぶマイコン講座
- 高速シリアル伝送技術講座
- 記録計/データロガーの基礎知識
- アナログ設計のきほん/ADCとノイズ編
- めざせ高効率! モーター駆動入門講座
- Bluetooth mesh入門
- 「SPICEの仕組みとその活用設計」最新記事一覧
- 計測器メーカーから見た5G
- USB Type-Cの登場で評価試験はどう変わる?
- IoT時代の無線規格を知る【Thread編】
- IoT時代の無線規格を知る【Z-Wave編】
複雑さを増すマイクロプロセッサ・アーキテクチャに立ち向かう
マルチプロセッサを用いたSoCアーキテクチャを採用し、うまく工夫することで、電力効率と性能の向上を両立することができる。
企業においてウイルスの侵入検出機能やファイアウォール・セキュリティ機能、ネットワークにおける高速プロトコル処理など、高い処理性能が求められるアプリケーションが増えてきている。これらのアプリケーションは、より多くのデータを扱うだけではでなく、より高度なパケット処理を行う必要がある。そうした処理を担うプロセッサは、性能の向上と、消費電力の抑制を両立させるという、非常に困難な課題に直面している。
従来は、プロセッサのクロック周波数を上げることにより、性能を向上させてきた。しかし、周波数を上げることは、もはや性能向上のための万能策ではない。チップが「電力の限界」に達してしまうからである。例えば、米Intel社のPentiumプロセッサはクロック周波数が4GHzで動作時に、100Wもの電力を消費する。
周波数を上げて行っても、チップ内部のアーキテクチャが限界に達し、CPUの動作に追従できないので、あまり効果が見られないか、あるいはかえって逆効果となってしまうこともある(図1)。アーキテクチャ内でバランスが崩れると、プロセッサの能力はI/Oやメモリーの処理速度に制約されるようになり、高い処理性能を実現できない。消費電力の許容範囲を広げたり、プロセッサのアークテクチャを変更したりすることなく性能を向上させるには、製造プロセスを最適化するだけにとどまらない革新的な技術が必要である。
 図1 システムごとの性能と消費電力 シングルコアアーキテクチャの性能が向上するに連れ、設計の複雑さと消費電力も増加する。周波数を上げていくと、プロセッサのアーキテクチャは電力の限界に達する。
図1 システムごとの性能と消費電力 シングルコアアーキテクチャの性能が向上するに連れ、設計の複雑さと消費電力も増加する。周波数を上げていくと、プロセッサのアーキテクチャは電力の限界に達する。性能向上のためのアプローチとしては、SoC(system on chip)集積技術やハードウエア・アクセラレーションが使われることが多い。性能を最適化する際には、厳しい電力要求に応えられるようにしなればならない。よく使われる方法として、マルチプロセッサを使って低い周波数で動作させるアプローチがある。これにより、周波数が高いプロセッサを1つ使うのと同等の性能が得られ、かつ、消費電力を著しく抑えることができる。例えば、4つの1GHzコアで、1つの4GHzコアと同等の性能を実現できるのだ。このとき、それぞれの1GHzコアが3Wで動作すると、4コアアーキテクチャの消費電力は12Wとなり、4GHz Pentiumで消費される電力のわずか12%で済むことになる。
性能を最適化する際には、こうしたアプローチを考慮に入れて、性能と電力効率の向上を図る必要がある。クロックゲーティングをきめ細かくするなど、設計方法を変えるとよい場合もある。マルチプロセッサ・アーキテクチャに移行する場合は、SoC設計の再考が必要である。高集積SoCはなおさらである。チップレベルの設計とボードレベルの設計では、まったく異なったものとなるからである。ソフトウエアの観点からは、アプリケーションを実行する際に、複数のコアで分散処理をさせるため、アプリケーション分割、使用可能なハードウエア・アクセラレーションリソースの効率的な利用、強靭なプロセッサ間通信メカニズム、および共有リソースの競合回避などが必要となる。これらを実現して、アプリケーションレベルで動的な電力管理を適用できるようになると、消費電力をかなり削減することができる。
SoCアーキテクチャを使う利点
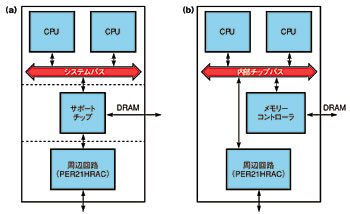 図2 ボードレベルのアーキテクチャとSoCアーキテクチャ 個々のデバイスから成るマルチプロセッサシステムでは、システムバスが、各プロセッサ間のアクセスとシステムリソースへのブリッジの役割を担う(a)。このボードレベルのアーキテクチャをそのままSoCに実装すると、同アーキテクチャの効率の悪さもSoCに引き継がれてしまう(b)。
図2 ボードレベルのアーキテクチャとSoCアーキテクチャ 個々のデバイスから成るマルチプロセッサシステムでは、システムバスが、各プロセッサ間のアクセスとシステムリソースへのブリッジの役割を担う(a)。このボードレベルのアーキテクチャをそのままSoCに実装すると、同アーキテクチャの効率の悪さもSoCに引き継がれてしまう(b)。SoC製造技術の進歩に伴い、マルチプロセッサ・サブシステム全体を1個のチップに集積することが可能となった。複数の部品を1つのチップ内に配置できるようになると、回路ブロック間の遅延が減少し、データの競合回避や一貫性の管理が行いやすくなる。回路ブロック間の遅延が減少すると、チップ全体としての性能が向上する。また、一貫性の管理ができるようになると、複雑なプログラミングが不要になり、性能の改善につながる。このアプローチはまた、別の面でも消費電力の節約に貢献する。信号はボード上ではなくチップ上を伝送するので、ドライバのサイズを小さくすることができる。このほかに、メモリーなどの共有リソースの効率も向上し、メモリーチップ数や必要なコントローラ数を削減できる。
SoC実装には、ボードレベルのアーキテクチャ上に部品を接続するのとは、大きな構造上の違いがある。SoC実装が、単にボードレベル実装の縮小版にすぎないのならば、どちらのアプローチをとっても同じ問題が生じることになる。ボードレベルのアーキテクチャと同じでは、SoCアークテクチャがもたらす効果は得られない。例えば、動作周波数が高いシングルコアのアーキテクチャでは、システムバスがプロセッサにデータを送る速度よりもCPUの動作速度が速くなると、メモリーバスに問題が発生する。高集積のSoCデバイスは、リソースをより細かく制御できるという特徴があるが、この特徴を活用しなければ、性能や電力効率を向上させることはできない。
複数のチップから成るマルチプロセッサシステムについて考えてみよう。各プロセッサはサポートチップを介してメモリーやI/Oにアクセスすることができる(図2(a))。ボードレベルのアーキテクチャをそのままSoCに実装した段階では、システムバスが内部チップバスになっただけで、アーキテクチャはほぼ同じである(図2(b))。サポートチップによりバス遅延はかなり減少する。しかし、ボードレベルのアーキテクチャをSoCに移行しただけでは、個々の部品はまだ論理的に独立した状態で、SoCの特性がうまく生かされていない。例えば、チップ間にバスを通す場合は、バス幅を最小限にすることが、端子数の管理や配線レイアウトの簡素化、基板面積の縮小、および全体としての消費電力の削減において最も重要な点である。しかし、配線がチップ上にある場合には、バス幅を小さくすることはあまり重要ではない。ボードレベル実装と同じ幅のバスをSoCに適用すると、不必要に制約を加えることになる。従って、ボードに実装された部品をそのまま配置するのではなく、SoC用に再設計することが大切である。すべての配線、共有リソース、およびそのコントローラのバランスを考察し直す必要がある。
集積化することで、システムを全体的にとらえやすくなり、リソースをより効率的に使うことができるようになる。例えば、メモリーコントローラやI/Oブリッジがオンチップに実装されていると、あらゆるCPU状態にもアクセスが可能になり、局所的またはシステムレベルのアクセスのスケジューリングに対して、最適な判断を下すことができる。オンチップ集積により可能となった新しい機能としては、L2キャッシュの共有とCPUコアごとのメモリーサブシステムがある。分散アーキテクチャと比較して、コア間のデータ受け渡し効率が向上する。共有キャッシュは、データの一貫性を管理しやすくなる。
マルチプロセッサシステムの心臓部となるのは、インターコネクト・アーキテクチャである。これは、種々のリソース間の通信を定義するもので、ひいてはデータの競合回避や一貫性の管理につながる。インターコネクト・アーキテクチャには主に、バス、リング、およびスイッチングの3つがある。共有バスはすべてのリソースを単一のバスに接続する。リングとスイッチは、リソースをポイントツーポイントで接続する。全体のシステム電力を最小限にするには、性能と一貫性管理のバランスを考えてシステムを構築する必要がある。
共有バスの最大の利点は、すべてのリソースからすべてのトランザクションが見えることである。ブロードキャスト機能により、データの一貫性管理を効率良く行うメカニズムが実現できる。例えば、単一バスのトランザクションは、それだけで一貫性管理のメカニズムを実現していることになる。なぜなら、すべてのプロセッサコア、キャッシュ、メモリーコントローラ、および高速I/Oが同一のバス上に存在するからである。低電圧の振幅技術を採用し、フル電圧振幅技術を回避すれば、バス電力も大幅に抑えることができる。
一方、スイッチでは、各システム回路ブロック間に必要な帯域幅は小さくて済む。しかし、統合された一貫性管理を行う場合など、他のリソースすべてと通信するためには、プロセッサは複数のバストランザクションを処理しなければならない。そのため、全体の遅延は増大する。例えば、4コアシステムでは、1つのコアは他の3つのコアそれぞれにトランザクションの要求を送信し、確認応答を受信しなければならないので、合計6つのトランザクションが必要となる。これに加えて、メモリーやI/Oコントローラを更新するためのトランザクションも必要となる。
ソフトウエア開発者の立場から見て、マルチプロセッサ・アーキテクチャへ移行すると、アプリケーション処理を複数のコアに分割させる必要があるため、ソフトウエア設計はより複雑になる。幸いなことに、高い処理が求められるアプリケーションは、VoIP(voice over internet pro-tocol)でサポートするチャンネル/ストリーム数を倍にしたり、100Mビット/秒から1Gビット/秒イーサーネットに移行する通信アプリケーションにおいて処理データを10倍にしたりといった具合に、基になるものがあり、それを数倍にするというケースが多い。その際、ソフトウエア開発者は、マルチプロセッサ・アーキテクチャ用のコードでも、慣れているシングルスレッド形式を使うことができる。共有リソースの管理に関しては、マルチプロセッサを意識してコードを開発することが必要である。
シングルコアの高速アーキテクチャにおいて、アプリケーションに対してアーキテクチャがバランスを失うと、バス帯域幅に制約が生じるという問題がある。マルチプロセッサ・アーキテクチャのSoC内部バス幅は広いため、帯域幅の制約は問題ではなくなる。それよりも、共有リソースのアクセスや一貫性を管理することの方が重要となってくる。例えば、1つのCPUコアがデータブロックを処理している場合、データを更新してから、更新データをメモリーに書き込むまでには遅延が生じる場合がある。ここで他のCPUコアがそのデータを使って処理を行おうとする場合、誤まった結果が得られる可能性がある。メモリーの一貫性メカニズムは、更新値を提供するか、または最初のCPUコアがデータを書き込み、更新を完了するまでデータをロックすることにより、この状況を回避する。
SoCアーキテクチャ自体に関していえば、SoCでは遅延と競合の問題は比較的明確であり、開発者はそれらを効率良く管理できる。また、ハードウエアによる一貫性管理を行えば、遅延を減少させることが可能になる。ソフトウエアによる一貫性管理では、実行サイクル数が多くなり、遅延と消費電力が増大してしまう。高度な処理が要求されるアプリケーションでは、性能と消費電力が互いに密接に関連しており、電力効率が5%改善すると、消費電力は5%削減される。
消費電力低減のための電力管理法
電力を削減するために最初にすべきことは、使用していない回路ブロックの電源を切ることである。多くのプロセッサには、周辺機器とシステムブロックが待機状態のとき、再び動作するまでスタンドバイまたはスリープモードに移行する機能がある。しかし、ネットワーキング、エンタープライズ・ストレージ、高密度コンピューティング、ワイヤレス・インフラストラクチャなどの高度な処理が求められるアプリケーションは、通常ほとんどフルで稼働しているため、このような電源管理手法ではあまり効果が得られない。電力削減のためには、アーキテクチャの能力を最大限に活用し、高い処理性能が得られるように工夫しながらも、CPUに無駄な待ち時間が生じたりするような、電力の無駄使いが起こらないプログラムを開発する必要がある。
マルチプロセッサ製品には、統合されたコントローラにより性能と消費電力を最適化する自動メカニズムを備えるものが多い。例えば、データの一貫性は非常に複雑な問題であり、CPU、キャッシュ、メモリー、およびI/Oの間でその問題を管理するメカニズムは、マルチプロセッサ・アーキテクチャを効果的かつ効率的なものとするために重要な部分である。
開発者は、不適切なプログラミングによって、これらのメカニズムを誤って壊してしまわないように注意しなければならない。例えば、システムをシングルコアからマルチプロセッサ・アーキテクチャへ移行する場合、キャッシュの一貫性の管理には注意が必要である。シングルコア実装では、CPUはキャッシュをフラッシュ(クリア)して、データをI/Oポートに送信する前にすべてのデータが更新されたことを確認しなければならない。データの一貫性をサポートしたマルチプロセッサ・アーキテクチャでは、キャッシュのフラッシュは不要である。ハードコーディングされたキャッシュフラッシュがあると、不必要に帯域幅と電力を消費し、性能の低下や遅延の増大につながる。
アプリケーションがメモリーにアクセスする方法を変更することも、効果的である。メモリーにアクセスする際には、個々に複数回アクセスするよりも、グループ化するか、アクセスが連続的に行われるようにするとよい。連続アクセスのグループ化では通常、同時にアクセスする複数のデータを、同一の物理メモリーラインまたはバンク内に配置する。システムは、アクセスするデータがすべて同じメモリーワードに存在する場合、1回の32ビットアクセスで、4つの連続する8ビットデータを読み出すことができる。関数内では、データを同一ページに配置するとページングのオーバーヘッドをなくすことができる。
種類別にグループ化する場合の1つのアプローチとして、読み出しと書き込みの列の順序を並べ替え、複数の読み出しを実行してから一度に複数の書き込みを実行するというものがある。このアプローチでは、不要なバスの方向転換、つまり、バスを読み出しトランザクションから書き込みトランザクションへ、またはその反対に変換する際の遅延がなくなり、全体の性能および消費電力が改善される。
いずれの場合も、グループ化をメモリーコントローラに完全に任せてはならない。メモリーコントローラは、メモリーリソースへの「公平なアクセス」を強制してしまうことがある。その結果、複数CPUからのトランザクションが、うまく並んだメモリーバースト、またはグループ化されたアクセスを分断してしまい、効率が低下する場合がある。
データをグループ化することで、実際には遅延が増大してしまうような、偽共有(false sharing)の状態が発生することがある。グループ化により最大の効果を得るためには、これを回避する方法を、アプリケーションレベルで理解しておく必要がある。4つのプロセッサコアのそれぞれに対して、インスタンスを持つシステムフラグがあるとする。ほとんどの場合、個々のフラグにアクセスするのはそれを保有するプロセッサのみである。4つのフラグを配列に割り当てれば、それらは物理的に連続したメモリーに配置されることになる。この場合、キャッシュに効率の悪い偽共有が生じる。キャッシュは複数バイトから成る複数ラインで構成され、各ラインは、CPUが保有する1つのメモリーまたはI/Oリソースに対応する。フラグの配列を定義すると、フラグはメモリー内に連続的に割り当てられる。つまり、システムがそれらをキャッシュに読み込むと、すべてのフラグが同一のキャッシュラインに属することになる。
一貫性を管理するプロトコルの1つに、MESI(modified exclusive shared invalid)がある。MESIでは、プロセッサまたは他のリソースがデータ列の書き込みを行いたい場合には、排他的な所有権を要求する。フラグ配列の例では、実際にはデータは共有されず、一貫性を管理する必要がないにもかかわらず、CPU間でキャッシュラインの所有権の取り合いが発生してしまう。
一貫性管理を行う場合、キャッシュラインへのアクセス権の取得に時間がかかる。このため、トランザクションは、キャッシュにデータがまったく存在しない場合と同じくらい遅くなってしまう。この遅延はそれほど気になるものではないが、取り除くことができる。異なる種類のデータがシステム全体にわたっていくつか存在すれば、全体としての遅延は大きくなる。また、キャッシュを消費すると、使用できるキャッシュ空間が減ってしまうことになり、キャッシュ効率が低下する。適切なプロファイリングツールや解析ツールを利用することにより、偽共有や意図しない共有が生じている状況を検出し、複数エージェントが無駄に同一キャッシュラインを奪い合う状態を避けることができる。
この例に対しては、配列に割り当てる代わりに、プロセッサフラグをレコードとして定義する方法がある。4つの対応するフラグをそれぞれグループ化するのではなく、プロセッサごとにグループ化する。そうすれば、連続するフラグは同一プロセッサのものなので、アクセスごとにキャッシュラインの所有権を変える必要がなくなる。
キャッシュ/メモリー関連の性能を改善するもう1つの方法は、ある関数が排他的に使用するデータを、他の関数が使用するデータから離して配置することである。特に、連続的に多くのデータの読み書きを行う関数に対しては、この方法が有効である。局所データと大域データを明確に区別すれば、別の形の偽共有を回避することができ、より効率的なバーストを生成することが可能となる。これにより、排他処理の要求が減少し、バスの方向転換も少なくなる。
プリフェッチも、キャッシュ効率を向上させる。例えば、パケットにストリーミングする場合は、ヘッダを直接L2キャッシュに割り当て、キャッシュラインを所有するI/Oポートがすぐに使用できるようにする。CPUが1度だけ参照するペイロードは、キャッシュに入れる必要はなく、これにより、まだ使用するデータをキャッシュから追い出さずに済む。キャッシュに入れるべきデータをうまく制御すれば、キャッシュ効率は向上する。ここでも、性能を向上させれば、消費電力も改善する。効率良くメモリーやキャッシュを使用することが、性能や消費電力の改善に直接つながるのだ。
ハードウエア・アクセラレーションを利用する
処理によってはハードウエア・アクセラレーションが適しているものもある。再構成可能なアクセラレーションエンジンによりハードウエア化すると、メインCPUコアの負荷が軽減して、性能が改善し、消費電力は低下する。例として、チェックサム計算について考えてみよう。チェックサム計算は、受信データが破損していないことをある程度保証するものなので、データの完全性を保証する多くのメカニズムにおいて必須である。データを受信したら直ちにサムを計算しなければならない。エラーが存在するのであれば、最終的に破棄するデータの処理に、サイクルを消費するのは無駄だからである。また、データの破損を早く確認できれば、再送を要求して、再送メカニズムを迅速に開始することができる。
ハードウエア・チェックサムエンジンがあれば、どのように、いつ参照するかにもよるが、DMA(direct memory access)を使って、受信データを内部または外部メモリーに直接置くことができる。この方法ならばCPUには何の負荷もかからない。データはCPUからの要求があればすぐにロードできる状態になる。しかし、サムを確認するには、データをCPUに渡す必要がある。データをメモリーに配置した後では、CPUはデータをチェックサム演算に使用する前に、メモリーから読み出すという追加の処理が必要になる。
その他の方法としては、メモリーコントローラがDMAによりデータを直接キャッシュに配置することにより、ロード操作を高速化することができる。しかし、この場合は、永続的なコピーを残すために、CPUは結果をメモリーにストアしなければならない。このため、チェックサムサイクルが1つ余分に必要となる。
プログラム可能なチェックサムエンジンならば、受信データのチェックサムはどのCPUでも処理可能となる。つまり、チェックサム演算、ロード、ストアの各サイクルが並列に処理されることになり、処理上の遅延は減少する。また、チェックサムエンジンによる処理は、CPUによる処理よりも消費電力が少ない。CPUによる処理を回避することにより、キャッシュに存在する使用頻度の高いデータをフラッシュせずに済む。
理想的には、アクセラレーションエンジンそれ自身が汎用的である方がよい。チェックサムを計算するのと同一のエンジンで、CRC(cyclic redundancy check:巡回冗長検査)の計算や、RAID(redundant array of independent disk)アプリケーション用のXORシグネチャの生成もできることが望ましい。また、CRCなどの関数は、1つのアプリケーション内では固定のアルゴリズムだが、エンジンは関数の実装方法を指定するための再設定可能な要素をサポートできるとよい。例えば、外部TOE(TCP/IP offload engine)が使用されている場合は、プロセッサまたはTOEのいずれかでCRCエンジンをオフにする必要がある。インラインTOEなどのエンジンがプロセッサの外部にある場合は、複数CPU用に複数のデータストリームのキューを持つことが必要となる。
同期を回避することは、リソースを共有するための鍵となる。過度に同期が必要になると、そのオーバーヘッドが、マルチプロセッサ実装にとどまってしまう要因の1つとなる。2つのCPUがイーサーネットMAC(media access controller)を共有する例を考えよう。通常、ステータスレジスタは、CPUがステータスを読み出すと自分自身をクリアする。従って、最初に読み出しを行うCPUはステータスを得ることができるが、もう一方のCPUはステータスを得ることができない。そこで、MACステータスレジスタを手動でクリアすることにすると、今度は、ステータスを得るべきすべてのCPUが読み出しを終えたかどうかを確認して、クリアしてもよいかどうかを判断しなければならないという問題が生じる。そのほかにも、出力キューへの追加時に、現在のキューの末尾を認識するために他のCPUと同期をとらなければならないといった問題が存在する。これらの問題を解決するためにいちいちCPU間で同期をとっていたのでは、サイクル数がたくさん必要となり、単純なI/Oトランザクションが非常に複雑なものとなってしまう。
SoCでは、2つの方法で、単一のリソースを複数CPUに分割し、競合を回避する。まず、統合されたコントローラが、CPUごとに個別のキューと割り込みを管理し、各CPUが互いに独立して自分自身のデータストリームを制御できるようにする。また、コントローラがすべての同期を解決する。ソフトウエアによる再構成により、各CPUが優先度や特殊なトランザクションを指定することが可能である。コントローラはトランザクションを最適化することもできる。例えば、複数の連続するトランザクションをグループ化したり、外部コントローラでは不可能な巧みな方法でリソースを共有したりすることが可能だ。コントローラは、受信した情報を区別して、それぞれ適切なCPUに送る。
2つ目の方法は、SoCのI/Oポートを変更して、複数CPUをサポートさせることである。例えば、CPUごとに1つずつ、MACに複数のステータスレジスタを持たせる。CPUごとに制御できるようにすることで、CPUはリソースを使用する前に互いに確認し合う必要がなくなる。
性能と消費電力を改善するもう1つの方法に、割り込みの制御がある。例えば、I/Oポートからのデータは複数CPU間で分割されることが多い。あるCPUがI/Oを占有しているときに、他のCPUにデータが来ると、I/O割り込みが生じ、I/Oを占有していたCPUは次のCPUにI/Oを引き渡さなければならなくなる。この引き継ぎに時間がかかり、CPUがI/Oを使用している時間が短くなってしまう。
ハードウエアベースの割り込み制御では、リソースを占有すべきCPUに直接割り込みを発行する。複数のCPUが同じリソースへのアクセスを要求している場合は、効率的に制御することが重要である。例えば、1つのCPUにI/Oポートからのすべてのパケットを受信させ、どのCPUにどのパケットを送るかを決定するための一切の負荷をそのCPUに負担させることができる。あるいは、ハードウエアによる制御により、公平なスケジューリングに基づいて、パケットを特定のCPUに直接送ることも可能である。
高性能アーキテクチャにおいては、消費電力の問題が付きまとう。ますます複雑化する多機能な機器をサポートするには、もはや単に動作周波数をあと何メガヘルツか増やせばよいというわけにはいかなくなっている。増大する消費電力の問題を解決するには、効率的にリソースを共有するために、単一チップ上にメモリーとI/Oを集積した、マルチプロセッサSoCアーキテクチャを検討する必要がある。競合を回避し、一貫性を管理する内部メカニズムにより、マルチプロセッサ設計の複雑さはかなり緩和される。マルチプロセッサ・アーキテクチャを理解すれば、シングルコア用のコードを、これらのメカニズムとうまく動作するようにポーティングして、性能の向上と消費電力の削減を図ることができる。
Copyright © ITmedia, Inc. All Rights Reserved.
記事ランキング




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。