- プロセスエンジニアの現場から
- マイクロプロセッサ懐古録
- 中堅技術者に贈る電子部品“徹底”活用講座
- たった2つの式で始めるDC/DCコンバーターの設計
- DC-DCコンバーター活用講座
- Wired, Weird
- マイコン講座
- Q&Aで学ぶマイコン講座
- 高速シリアル伝送技術講座
- 記録計/データロガーの基礎知識
- アナログ設計のきほん/ADCとノイズ編
- めざせ高効率! モーター駆動入門講座
- Bluetooth mesh入門
- 「SPICEの仕組みとその活用設計」最新記事一覧
- 計測器メーカーから見た5G
- USB Type-Cの登場で評価試験はどう変わる?
- IoT時代の無線規格を知る【Thread編】
- IoT時代の無線規格を知る【Z-Wave編】
SoC内部の相互接続アーキテクチャ:増加するトラフィックを効率良くさばく(3/3 ページ)
実際の設計手法
オンチップネットワークを構築する基本的な手法としては、リンクと調整リソース(shaping resource)の2種類がある。リンクは、ブロック間のデータパスを提供するものである。共有バスの一部、専用の接続ポイント、スイッチネットワークの経路など、さまざまな方法でこれを実装することができる。一方の調整リソースには、キャッシュ、FIFO(first in first out)、キューイングエンジン、並べ替えバッファ(reorder buffer)などがある。
従来型のCPUバスアーキテクチャからより強力な方式へと移行する最も容易な方法は、おそらくバスをセグメント化することだろう。Janac氏は、「マルチメディア向けSoCでは、トラフィックを低遅延の処理、広帯域幅の処理、それほどクリティカルではない周辺処理に分割することにより、この目標を達成することができる」と説明する。このようなセグメント化を行った上で、それぞれの処理を別々に実装するのだ。その際、複数のバス接続を有するブロックが生じても構わない。米Denali Software社のIP製品担当バイスプレジデントであるBrian Gardner氏は、「この手法であれば、トラフィックの種類に応じてそれぞれに適切な物理媒体を使うことができる。それだけでなく、モデリング精度を高め、同様の方法によってモデル化可能なデータフローにも対処できる」と指摘する。
「この手法を適用すると、階層型の相互接続が得られることが多い」とLautzenheiser氏は述べる。このことは、米Raza Microelectronics社のネットワークプロセッサのアーキテクチャ「XLR」にはっきりと現れている(図1)。いくつかの機能ブロックの内部にも、同様の様子がうかがえる。例えば、「ARM Cortex A9」など最新型のCPUからもそうしたことが見てとれる。そこでは、専用リンクによって処理コアとL1キャッシュ(命令/データ)が接続されている。一方、マルチマスターの高速キャッシュバスは、L1キャッシュとL2キャッシュを接続し、最大4個のプロセッサコアに対応する。制御/監視ロジック用の別のリンクは、バックグラウンドに控えている。L2コントローラには2本のシステムバス接続が用意されている。
しかし、各データフローに適切な物理的リンクを用意することが非実用的である場合にはどうすればよいのだろうか。その良い例が、チップ上の複数のプロセッサからどのようなトラフィックの組み合わせが生じようとも、何とかしてそれをDDR SDRAMが受信可能な整列されたコマンドストリームに整形しなければならないSoCのDRAMコントローラである。この問題の複雑さを理解するために、そのようなハイエンドのDRAMコントローラの内部を見てみよう(図2)。
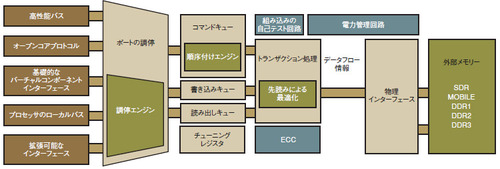 図2 ハイエンドのDRAMコントローラ キューイング、並べ替え、サービス品質の機能を持つプロセッサの列として構成されている。
図2 ハイエンドのDRAMコントローラ キューイング、並べ替え、サービス品質の機能を持つプロセッサの列として構成されている。このデバイスでは、複数の独立した段階に分けてトランザクションを処理する。まず調停エンジンが、優先度に基づいてコントローラへのアクセスを決定する。次にコントローラはコマンドキュー、読み出しキュー、書き込みキューに要求をロードする。ここではサービス品質に対する要求と実際のDRAMのタイミングに基づく並べ替えのために待ち時間が発生する。最後にトランザクション処理エンジンへと要求が渡される。ここではキューを先読みし、DRAMの使用法を最適化するための要求の再構成と収集が行われる。
ほかの機能ブロックにおいても、これと同様の考え方が適用されるようになってきている。信号処理ブロックやエンコーダ/デコーダブロックには、処理の分散と集約、データの並べ替え、ランダムな要求をバースト要求に変換するためのバッファリングなど、DRAMコントローラと同じ多くの機能を提供する高度なDMAエンジンを搭載したものが増えている。しかし、このような機能を実行するエンジンにより、トラフィックを物理的リンクに適応させるDRAMコントローラの負担が軽減されることはない。実際、これらのエンジンにより、DRAMコントローラの負担は増大している可能性がある。
ツールの問題、技術の問題
ここまで述べてきた手法を適用することで、かなりの効果を得ることができる。MIPS社の社長兼CEOであるJohn Bourgoin氏によると、「SoCにチューニングを施せば、基本的に同じ機能ブロックでもシステム性能を4〜5倍も改善できる」という。つまり、CPUをアップグレードしたり、より高速なプロセスを利用したり、場合によってはハードウエアアクセラレータを追加したりするよりも、大きな性能向上が得られるということである。
SoCのアーキテクチャが、機能的に分割されたヘテロジニアスなマルチプロセッシングから、準対称的なマルチプロセッシングへと移行するのに伴い、相互接続アーキテクチャの位置付けは、性能の向上と消費電力の低減のための手段から、システム設計に必須のものへと変わりつつある。データフローを詳細に解析しなければ、マルチプロセッシングシステムでは配線が複雑になり、手ごろな価格でチップを設計することができなくなってしまう恐れがある。
この懸念は、再びツールの問題へと帰着する。Lautzenheiser氏によると、「設計者らがいまだにホワイトボードやスプレッドシートによって作業していることはないとしても、今日のツールフローは、ESLモデリングツールや、全体像はよく見渡せるがコーナーケースを完全に見落としがちなキューイング理論に基づく統計的解析、コーナーケースにも対応可能だがそれらを検出する速度が遅すぎるサイクル精度モデルを、その場しのぎで組み合わせているにすぎない」という。
Arteris社のJanac氏も、「アーキテクチャレベルのモデリングが必要だ」と指摘する。「問題は非常に複雑になり、もはやスプレッドシートでは対応できない。しかし、ESLでは、最高のツールを利用しても抽象的な解が示されるだけで現実的なものにはならない。従って、IPのサイクル精度モデルとシステムレベルの手法を組み合わせる必要がある」(同氏)という。
MIPS社のIntrater氏は、これを実現するための方法としてハードウエアエミュレーションの利用を提案する。「サイクル精度モデルはRTL(register transfer level)をベースとしており、Linuxのブートやアプリケーションの実行に用いるには低速すぎる。粗粒度の統計ツールをサイクル精度のシミュレーションと手作業で組み合わせることが、今日における最先端の手法である。しかし、初期の段階で配線のRTLモデルが用意されていれば、サイクル精度モデルを用いて数多くのサイクルをエミュレーションすることが可能になる」と同氏は語る。
このようなツールが出現したとしても、アーキテクチャを最適に構成するには技術が必要である。特にインターコネクトIPプロバイダによるシステムレベルのツールが徐々に出現してきても、適切なレベルで構造をモデル化し、ユーザーによる実際的な使用方法を正確に表したモデルを用意し、クリティカルなケースについて適切な個所に着目し、サイクル精度モデルから正確な結論を得るには、技術と経験が必須となる。ツールが登場したとしても技術の重要性に変わりはない。むしろ、チップ上に大規模なマルチプロセッシングシステムが搭載される時代へと移行するに連れ、不可欠なものとなるだろう。
バスのボトルネックの解消
通信システムやメディアストリームシステムにおけるデータ伝送速度は増大し続けている。それに伴い、データ伝送帯域幅がチップ設計の成功を握る主要因であると認識されるようになってきた。米Tensilica社は100以上ものマルチプロセッサチップを設計した実績を持つ。その経験から、帯域幅の問題を整理するためのいくつかの基本的な考え方が得られる。
例えば、データ通信が不適切に行われると、帯域幅の不足が生じる。I/O用のデータ通信、チップ外付けのメモリーとの通信、オンチップブロック間の通信に必要な合計実効帯域幅が、インターフェースの最大実効帯域幅を超えてしまうのである。これにより過度の遅延も生じる。データアクセスにおけるワーストケースの遅延、あるいは典型的な遅延によっても、全体的な帯域幅が十分でないために競合遅延がさらに増大するといった問題が発生する。
通信におけるボトルネックは、回路の複数の個所に存在する。最も問題となる個所は以下の3つである。
- オフチップのメモリーコントローラ
- プロセッサやDMAコントローラなどの複数のマスターが複数のスレーブ(メモリーやI/Oインターフェース)にアクセスする際のオンチップバス周辺
- プロセッサとバスとの間のインターフェース
プロセッサとバスとの間のボトルネックは、インターフェースにおける最大データ転送速度に依存する。この値は、オンチップバスの最大帯域幅に近い場合が多い。オンチップバスを介してデータにアクセスする従来のRISCプロセッサでは、データがすでにチップ上に存在し、プロセッサが途中でデータを変更しないとしても、データ転送に32ビットデータワード当たり10〜20のプロセッササイクルを要するだろう。
プロセッサとバスとの間のボトルネックを解消する方法は2つある。まず、別のプロセッサやDMAコントローラなど2つ目のバスマスターを用いて、データを1つ目のプロセッサのローカルメモリーに送受すれば、ボトルネックを部分的に緩和することができる。しかし、この方法では、RISCプロセッサにおけるレジスタの問題は残る。2つ目は、広帯域幅のデータストリームがバスインターフェースのボトルネックを回避できるように、プロセッサインターフェースを拡張することである。直接接続型のポートとキューを持つプロセッサであれば、プロセッサ実行ユニットを介して、RISCプロセッサより数桁も高速にデータ転送が行える。
バス接続とバス以外の接続を、複雑なチップ設計内で調和を保ちながら共存させることも可能である。2つのサブシステムが広い帯域幅とある範囲内に遅延を抑えることを必要とすることを設計者が認識しているならば、それらの間のパスを最適化すべきであることに気付くはずだ。ほかの部分の通信においても、帯域幅はそれほど必要としないが遅延に対する要求は高いデータを送受するために、共通のマルチマスター/マルチスレーブのオンチップバスを安全に利用することができる。このような分離手法により、共通バスの汎用性を維持しつつ、競合が生じる危険性は回避しつつ、モデル化を容易にし、プラットフォームの性能の拡張性を高めることが可能になる。
帯域幅の広い接続個所においても、通信を最適化することでエネルギ効率を上げられる。プロセッサ間の通信キューのような直接的な接続は、バスベースの同等の伝送と比較して、データ当たりの消費エネルギが1/10程度であることが多い。
Copyright © ITmedia, Inc. All Rights Reserved.
記事ランキング




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。